Übersicht
Obwohl traditionelle Indizierungsmethoden robuste Anfragezeiten bieten, haben sie eine klare Schwachstelle. Der Index muss in einer separaten Initialisierungsphase erstellt werden, bevor er zur Anfragebeantwortung verwendet werden kann. Um diese Initialisierungsphase zu minimieren, wurden verschiedene adaptive Methoden vorgestellt. Die Kernidee aller adaptiven Indizierungsmethoden ist es, den Index schrittweise zur Anfragezeit anhand der Anfrageprädikate zu entwickeln. Zu Beginn liegen keinerlei Informationen über die zu indizierende Spalte vor. Die erste Anfrage partitioniert nun die Spalte, so dass alle Einträge, die zur Beantwortung der Anfrage benötigt werden in einer Partition liegen. Zusätzlich wird gespeichert, welche Partitionen welche Bereiche beinhalten. Nachfolgende Anfragen partitionieren dann diejenigen Partitionen weiter, in die ihre Anfrageprädikate fallen. Dadurch wird die Spalte schrittweise mehr und mehr sortiert und indiziert. Leider bringt dieses adaptive Konzept verschiedene Probleme mit sich, z.B. eine niedrige Konvergenzgeschwindigkeit sowie hohe Varianz in Bezug auf Anfragezeiten.Idee
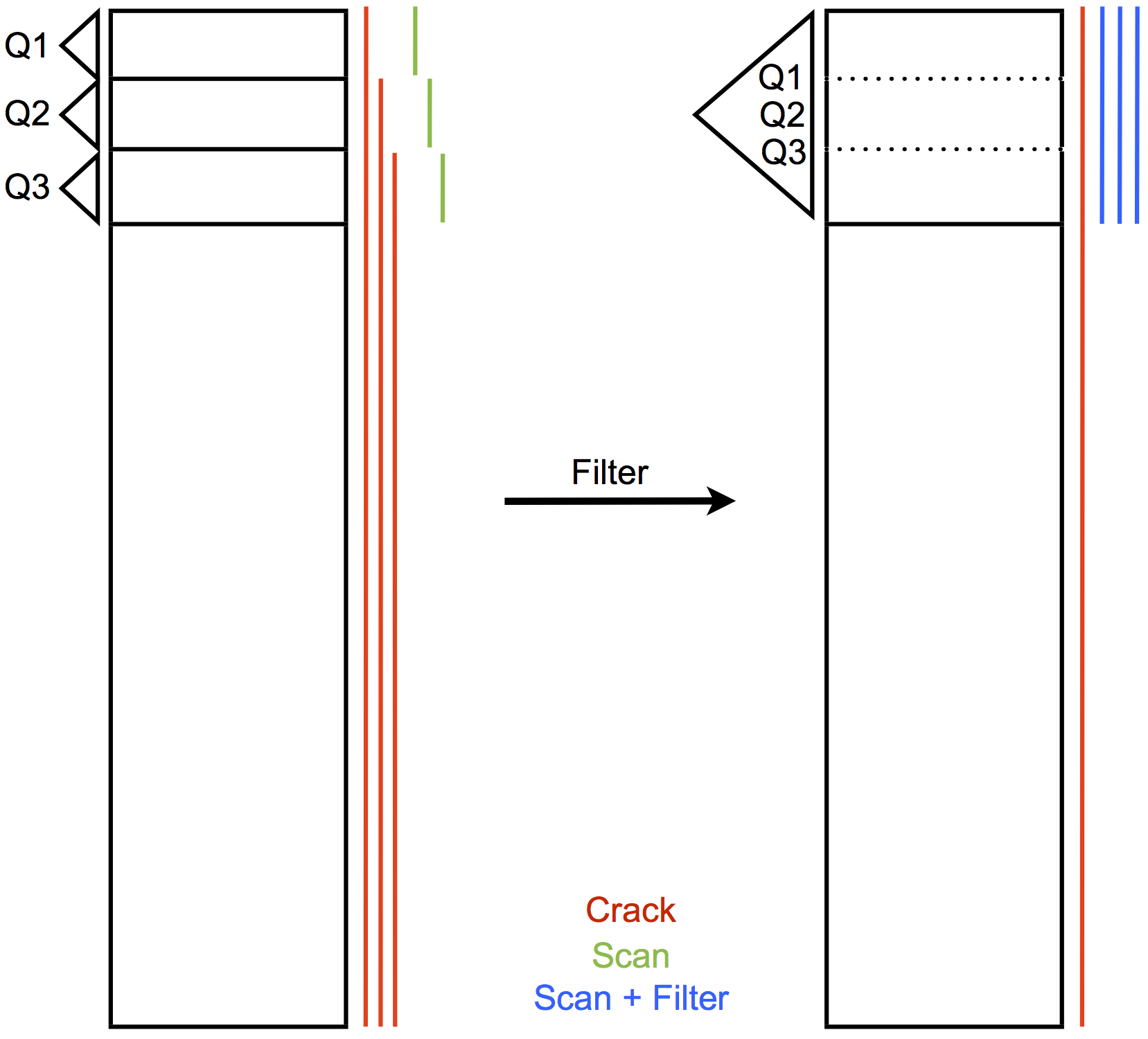
Bisher haben alle existierenden Methoden immer genau eine Anfrage betrachtet, bevor es zur Weiterpartitionierung kam. D.h. die Anfrage, die den Index benutzt, reorganisiert diejenigen Partitionen, die von der Anfrage betroffen sind. Dieses Konzept funktioniert gut für gleichverteilte Zufallsanfragen, die logisch nicht miteinander verknüpft sind. Ein sequenzielles Zugriffsmuster führt jedoch zu einer langsamen Konvergenz, da große Teile des Indexes wiederholt gelesen werden müssen und der Index sich pro Anfrage kaum weiterentwickelt. Stochastic Cracking [3] reduziert dieses Problem, indem zusätzliche, auf zufälligen Prädikaten basierende Partitionierungen angewendet werden. Dies führt zu einer gleichmäßigeren Entwicklung des Indexes. Zugleich bringt dieses Konzept aber zusätzlichen Ballast mit, der zur ohnehin schon teuren Anfragephase hinzu kommt.Daher werden wir versuchen, die Prädikate zu filtern anstatt Neue hinzuzufügen. Dazu betrachten wir eine Menge von Anfragen bevor wir eine Entscheidung treffen. Wenn beispielsweise mehrere Prädikate dicht beieinander liegen, könnte es günstiger sein, nur eines der Prädikate tatsächlich anzuwenden. Die Anfragen, die nun nicht mehr direkt beantwortet werden können, müssen den entsprechenden Bereich nachträglich filtern. Die Abbildung verdeutlicht das Konzept anhand eines Beispiels. Offensichtlich wurde der Cracking-Aufwand deutlich reduziert. Auf der anderen Seite müssen nun größere Bereiche gefiltert werden, um alle Anfragen zu beantworten.
Dieses Konzept bringt einige interessante Fragen mit sich:
- Wie werden Anfragen gruppiert, d.h. wie bestimmt man die Größe des Betrachtungsfensters?
- Wie entscheidend man, welche Prädikate man filtern soll?
- Werden Prädikate nur gefiltert, oder sollten auch welche ersetzt/modifiziert werden?
- Wie werden in diesem Zusammenhang nicht-uniform verteilte Schlüssel behandelt?
- Ist es möglich, einen Kostenabschätzer zu entwickeln, der alle diese Entscheidungen automatisiert?
Organisation des Proseminars
-
Meilenstein 1
Bekommen Sie einen Überblick über adaptive Indizierung, indem Sie die Kernliteratur über Database Cracking [2] und Stochastic Cracking [3] lesen. Machen Sie sich mit dem Quellcode vertraut, der von uns gestellt wird. Das Programm ist in C/C++ geschrieben und beinhaltet bereits Implementierungen von Standard Cracking und Stochastic Cracking (MDD1R). Des Weiteren enthält es Code für die Generierung von Testanfragen und Testdaten. Wenden Sie sowohl eine Anfragemenge, die einem zufälligen Zugriffsmuster folgt als auch eine, die einem sequenziellen Zugriffsmuster folgt, auf die Testdaten an. Testen Sie dabei beide Methoden (Standard/Stochastic Cracking) und analysieren Sie deren Verhalten. Visualisieren Sie die Ergebnisse mit Gnuplot [1] und präsentieren Sie sie im Seminar. -
Meilenstein 2
Entwerfen Sie ein System, das Prädikate filtern kann. Dieses System soll zwischen dem Anfragenstrom und dem Cracking Algorithmus platziert werden. Der Filter nimmt eine Menge von Anfragen entgegen, modifiziert diese und gibt sie an den Algorithmus weiter. Zusätzlich muss weitergegeben werden, welche Anfragen immer noch direkt beantwortet werden können und welche nachträglich filtern müssen. Bedenken Sie in Ihrem Design Parameter, um den Filterungsprozess justieren zu können. Präsentieren Sie Ihr Design im Seminar, um Probleme und Schwachstellen vor der Implementierung zu erkennen. -
Meilenstein 3
Implementieren Sie Ihr Design. In dem Programm, das Ihnen zur Verfügung gestellt wurde, ist ein Filter ohne Funktionalität bereits enthalten. Lassen Sie Ihre Implementierung gegen Standard und Stochastic Cracking antreten, die jeweils nur eine Anfrage betrachten. Variieren Sie wieder das Zugriffsmuster und finden Sie die besten Parameter für Ihr System. Testen Sie des Weiteren, wie Ihr System sich unter einer nicht-uniform verteilten Schlüsselmenge verhält und präsentieren Sie Ihre Ergebnisse im Seminar. -
Meilenstein 4
Versuchen Sie, basierend auf den Erkenntnissen des dritten Meilensteins, den Prozess der Parameterjustierung zu automatisieren, so dass der Filter komplett autonom arbeitet. Präsentieren Sie Ihre Ergebnisse in Form eines abschließenden Vortrages.
Details
-
Dozent
Prof. Dr. Jens Dittrich
-
Assistent
Felix Martin Schuhknecht -
Zeit/Ort
Unser erstes Treffen findet am Dienstag, dem 15.10.2013 um 12:15 Uhr statt.
Wöchentliche Treffen, Donnerstags, 12:15 Uhr
Raum: 3.06, Gebäude E 1.1
Ziele der Veranstaltung
- Erster Kontakt mit Forschungsarbeit.
- Präsentieren/Diskutieren von (eigenen!) Forschungsergebnissen in der Gruppe.
- Bachelor-/Master Arbeit mit Bezug auf das Thema möglich.
Referenzen
-
Gnuplot
www.gnuplot.info -
Stratos Idreos, Martin Kersten, and Stefan Manegold
Database Cracking
CIDR 2007 -
Felix Halim, Stratos Idreos, Panagiotis Karras, and Roland H. C. Yap
Stochastic Database Cracking: Towards Robust Adaptive Indexing in Main-Memory Column-Stores
PVLDB 2012 -
Felix Martin Schuhknecht, Alekh Jindal, Jens Dittrich
The Uncracked Pieces in Database Cracking
VLDB 2014/PVLDB 2013.