About this Project/News
Oct 9 2020: slides for undergrad lecture Big Data Engineering available here.
July 9 2019: pdf of the book is now available for free here.
March 3 2016: Request a lecturers copy of patterns in data management here.
March 1 2016: both the ebook and the paperback (with color graphics!) are now available at amazon: Patterns in Data Management: A Flipped Textbook (English Edition)
Feb 3 2016: ebook now available at amazon: Patterns in Data Management: A Flipped Textbook (English Edition)
Dec 9 2015: excerpt from my new book Patterns in Data Management available for download
Dec 14 2015: book walkthrough:
This page contains a directory of instructional videos in English about database technology. As of September 2014 roughly half of them, this is about 80 videos, are in English (the ones starting with 14.**). Those videos are mainly about the algorithms, index structures, data layouts and other important technologies required to make databases perform very well on large datasets. People are also calling this stuff "big data" these days, whatever that hype term means. So if you feel like that sounds cooler in your CV, you may assume that thes videos are about big data technologies. The video material handles traditional disk-based and main-memory techniques at the same time wherever possible. You will learn that often very similar techniques are used at different levels of the storage hierarchy. At Saarland University I use this material for my flipped classroom (aka inverted classroom) on database technology. At Saarland University this course is offered as a 4+2 "core" lecture, i.e. this lecture can either be attended in the third year of your BSc or as part of your MSc. The first instance of this flipped classroom happened in summer term 2014. The second will happen in winter term 2014/15 (with some minor changes here and there, in particular a slightly reduced workload).
Notice that below each video in the listing below there is a link to downloadable slides used to produced that video, each in two versions: 1. original slides , and 2. inverted colors for easier printing.
The videos are also publicly available through my youtube channel which you may subscribe to here to not miss any new videos:
If you have any comments on this material, any praise, bugs, etc: send me an email.
Über dieses Projekt
Diese Seite enthält ein Verzeichnis von kurzen Lehrvideos auf Deutsch zum Thema "Einführung in Datenbanken" sowie weiter Videos zu Datenbanktechnologie auf Englisch (siehe "About this Project"). Die Themen der deutschen Videos sind Entity-Relationship-Modellierung, Relationales Modell, Relationale Algebra, SQL, etc. D.h. es wird der gesamte Zyklus vom Planen einer Datenbank bis zur Erstellung und Nutzung unterrichtet.
Es gibt derzeit ca. 70 Lehrvideos auf Deutsch. Unter jedem Video sind zusätzlich die Folien zum Herunterladen verfügbar in zwei Versionen: 1. orignal, 2. invertiert (d.h. mit invertierten Farben, um das Ausdrucken zu vereinfachen).
Diese und weitere Videos sind auch öffentlich zugäglich auf youtube in meinem Kanal jensdit.
Den Kanal kann man hier abonnieren:
Einiges nützliches Material zu den Videos:
Fotoagentur: Schema und Daten für PostgreSQL; E/R-Modell und Relationales Modell
Datenbanken: Was muss ich wissen?
Im Sommersemester 2013 hatte ich angefangen, dieses Material zu erstellen, und für einen Flipped Classroom (auch Inverted Classroom genannt) an der Universität des Saarlandes genutzt. Die Vorlesung wurde von der Fachschaft Informatik mit dem Busy Beaver Teaching Award für die beste Grundvorlesung der Informatik ausgezeichnet.
Für Dozenten im Bereich Informatik: Meine Erfahrungen mit der Vorlesung im Sommersemester 2013 kann man hier nachlesen: Die Umgedrehte Vorlesung - Chancen für die Informatiklehre erschienen im Datenbank-Spektrum, November 2013.
Im Sommersemester 2014 lief die Vorlesung mit diversen Änderungen zum zweiten Mal. Für das Sommersemester 2015 sind wiederum ein paar Änderungen und Erweiterungen geplant.
Falls Sie irgendwelche Anmerkungen, Kommentare, Fehler, etc. zu dem Material haben, schicken Sie mir bitte eine email.
Search Results
Database Systems
Informationssysteme
- 5.1 Relationen versus Tabellen
- 5.2 Basisoperatoren: Selektion, Projektion, Vereinigung, Differenz, Kreuzprodukt, Umbenennung
- 5.3 Abgeleitete Operatoren: Schnitt, Theta Join, Equi Join, Natural Join
- 5.4 Abgeleitete Operatoren: Semi Joins, Anti Semi Joins
- 5.5 Abgeleitete Operatoren: Äußere Joins
- 5.6 Erweiterungen: Gruppierung und Aggregation
- 10.1 Schemadesign
- 10.2 Funktionale Abhängigkeiten, Functional Dependencies (FD)
- 10.3 Superschlüssel, Kandidatenschlüssel, Primattribute, Triviale FD, Erste und Zweite Normalform
- 10.4 Dritte Normalform 3NF
- 10.5 Boyce-Codd Normalform BCNF
- 10.6 Inferenzregeln, Hülle
- 10.7 Zerlegung, gültig, verbundtreu, verlustlos, abhängigkeitsbewahrend
0.1 Course Overview and Motivation
0.1.1 The Truth about Databases
Why is database systems a vertical topic? Which are those topics? Is this lecture only about database systems or software in general?
| Additional Material | |
|---|---|
| Further Reading | |

0.1.2 Architecture of a DBMS
What are the different software layers of a database system? How do they relate do the different vertical topics? What are the major tasks of store, indexer, and query optimizer? What are system aspects? What is the conflict of computation versus data access about? And does this conflict relate to the different layers of a database system?

0.1.3 Structure of this Course
How is the material covering the different database layers mapped to the weeks of the semester? What exactly does the recursive/iterative structure mean?
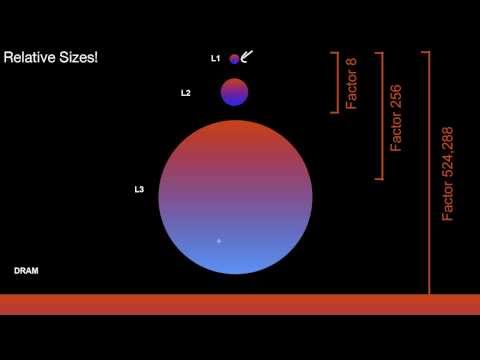
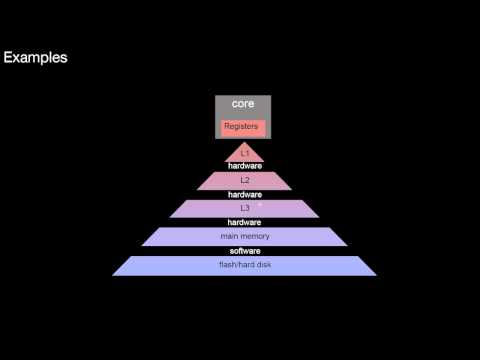
1.1 Storage Hierarchies
1.1.1 A Simple Storage Hierarchy
What are the properties of ideal computer memory? What is the core idea of the storage hierarchy? What is the relationship of storage capacity and access time to the distance to the computing core? What is the relationship of costs/bandwidth to the distance to the computing core? What are typical access times? How does this translate to relative distances? What are typical sizes of the different storage levels? How do they translate to relative distances? What are the tasks of each level of the storage hierarchy? How would I use a storage hierarchy to cache only reads? How do I use a storage hierachy to cache both reads and writes? What is inclusion? What is a data replacement strategy?
| Additional Material | |
|---|---|
| Literature |
|
| Further Reading |
|
1.1.2 The All Levels are Equal Pattern
What is the central observation here? What does this mean for practical algorithms? How can I exploit this to solve a problem on a specific layer of the storage hierarchy? How to misunderstand this pattern?
1.1.3 Multicore Storage Hierarchies, NUMA
How are the two terms core and CPU related? How does a typical multicore storage hierarchy look like? What is different compared to the storage hierachy? Why isn't L1 shared as well among multiple cores? What is a Non-Uniform Memory Access (NUMA) architecure? What is different compared to the multicore architecture? What does this imply for accesses to DRAM? Bonus Question: How again does this relate to The All Levels Are Equal?
| Additional Material | |
|---|---|
| Further Reading | |

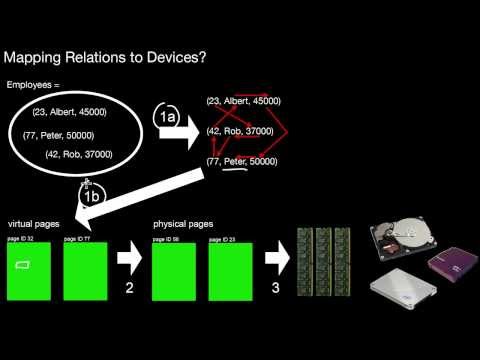
2.1 Overview
What are the principal mapping steps from relations to devices? Which of those steps are related to data layouts? Why linearize tuples? Why linearize values? And which comes first?
3.1 Motivation for Index Structures, Selectivities, Scan vs. Index Access on Disk and Main Memory
What are the major analogies of indexing in real life? Why index? What is selectivity? What is high selectivity? What is low selectivity?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |

4.1 Join Algorithms
4.1.1 Applications of Join Algorithms, Nested-Loop Join, Index Nested-Loop Join
Why are joins important? What are typical applications in data management? What is the possible impact of joins on query performance? What are the four principal classes of join algorithms? What is nested-loop join (NL)? What is its runtime complexity? For which type of join predicates does it work? What is index nested-loop join (INL)? What is required to run this algorithm? For which type of join predicate does it work? What is the runtime complexity of this algorithm?
| Additional Material | |
|---|---|
| Literature |
|

4.1.2 Simple Hash Join
How does simple hash join (SHJ) work? What is the relationship to index nested-loop join?
| Additional Material | |
|---|---|
| Literature |
|

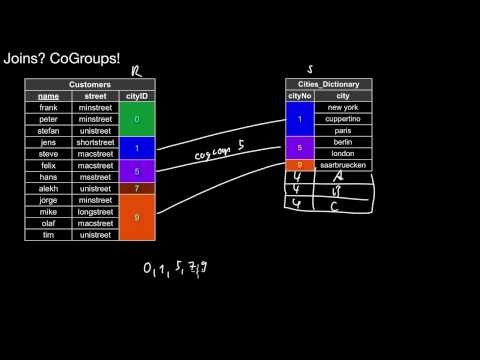
4.1.3 Sort-Merge Join, Co-Grouping
How does sort-merge join (SMJ) work? What does the algorithm do in principle? What has to be considered when deciding which pointer to move forward? How would I treat a situation where duplicates exist in both join columns? What is the relationship of joins and CoGroups? What is CoGrouping?
| Additional Material | |
|---|---|
| Literature |
|
4.1.4 Generalized Co-Grouped Join (on Disk, NUMA, and Distributed Systems)
Why are CoGroups a general property of joins rather than a property of a specific join algorithm? What is the core idea of generalized co-grouped join? Which three special cases can be implemented with this algorithm? What does the group()-function do in the algorithm? Which phases can be identified in the algorithm? Which algorithm executes the actual join then? Could that be a cross product? How can Generalized Co-Grouped Join be optimized to avoid calling that algorithm in certain cases anyhow?
4.1.5 Double-Pipelined Hash Join, Relationship to Index Nested-Loop Join
When does it make sense to consider using double-pipelined hash join? How does the algorithm work? In what sense is this algorithm symmetric? What is double-pipelined index join? What is the relationship to Index Nested-Loop Join? Does Double-Pipelined Hash Join have a Build and a Probe Phase? What is the difference of DPHJ and INLJ w.r.t. the join results produced over time?

5.1 Overview and Challenges
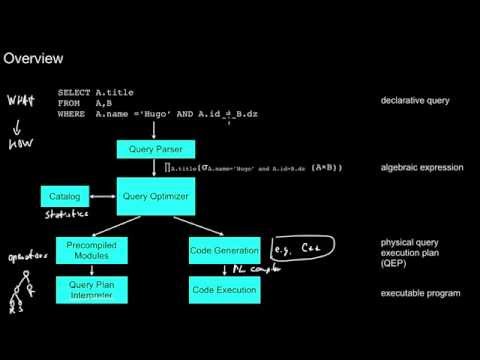
5.1.1 Query Optimizer Overview
What is the task of the query parser? What is the high-level task of the query optimizer? What is the relationship of the WHAT and the HOW aspects in that process? Why would the query optimizer need statistics about the data? Where does it obtain those statistics? What is query plan interpretation? What is the relationship of query optimization and programming language compilation?
| Additional Material | |
|---|---|
| Literature | |
| Video | |
5.1.2 Challenges in Query Optimization: Rule-Based Optimization
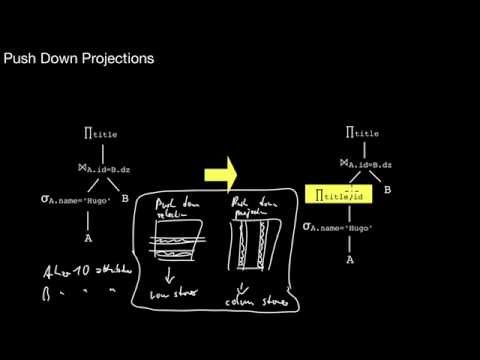
What is the canonical form of a query? When would that be a DAG (directed acyclic graph)? What does rule-based optimization do in principle? What does a single rule do? Why would I break up conjuncts of selections? Why does it make sense to push down selections? When exactly is that possible? Why should I strive to introduce joins whenever possible? And when is that possible anyway? When is it possible to push down projections? What has to be considered when doing this? What does the data layout of the store have to do with pushing down projections? So what are the most important rules?
5.1.3 Challenges in Query Optimization: Join Order, Costs, and Index Access
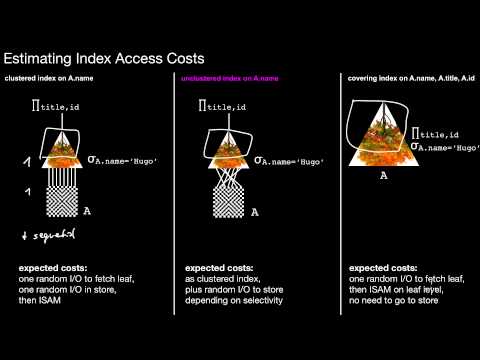
What is join order? What may be the effect of picking the wrong join order? Does this problem only occur for joins? How do I pick the right access plan? (OK, not at all, the query optimizer does this...) How does the query optimizer decide which access plan to take? What are the possibly different costs of picking a scan, clustered index, unclustered index or covering index? How could I estimate those costs in a disk-based system? Why should I be very careful with unclustered indexes? What may happen if the selectivity estimates of a query are wrong?
| Additional Material | |
|---|---|
| Literature | |
5.1.4 An Overview of Query Optimization in Relational Systems
What is a physical operator? What is the algebraic representation of a query? What is a cost estimation in the context of the query optimizer? What type of search space did System-R use? What must be considered when applying these transformations? What is an interesting order? Do bushy join sequences require materialization of intermediate relations? When would they not?
| Material | |
|---|---|
| Literature | |
| Additional Material | |
|---|---|
| Literature | |
6.1 Core Concepts
6.1.1 Crash Recovery, Error Scenarios, Recovery in any Software, Impact on ACID
What are possible error scenarios? What could be the impact of a power failure to the database buffer? What does the term `recovery' mean? Is recovery just important for database systems? What is the impact of error scenarios on ACID? What is a local error? How may it occur? What is redo? What is undo? What does losing main memory mean? What if we lose (some) external storage? How do we cope with this?
| Additional Material | |
|---|---|
| Literature | |

6.1.2 Log-Based Recovery, Stable Storage, Write-Ahead Logging (WAL)
What is `stable storage'? What is its relationship to the database store? What is the relationship to logging (as of video 14.163)? What is write-ahead logging (WAL)? What is and what is not allowed following WAL? What does WAL imply when committing transactions? What does WAL imply for the database buffer page eviction of dirty pages?
| Additional Material | |
|---|---|
| Literature | |

6.1.3 What to log, Physical, Logical, and Physiological Logging, Trade-Offs, Main Memory versus Disk-based Systems
What is physical logging? What are its pros and cons? What is an after image and a before image? And how big may those images become? What is logical logging? How does logical logging from physiological logging? How do log entries for the three variants typically look like? What are the performance trade-offs for the different logging variants? In a disk-based system? In a main-memory system? Why do the trade-offs differ so much in the two types of systems? How would you log data in a main memory system? What is the relationship to dictionary compression?
| Additional Material | |
|---|---|
| Literature | |

7.1 Introduction to NoSQL
What is a key-value database? What is an aggregate-oriented database? What is a column family? What is the value in a document database? What is the relationship of these aggregates and clustering, i.e. like in clustered indexes? When is an aggregate-oriented database a disadvantage? Are graph databases aggregate-oriented? Are relational databases good at managing relationships? What is BASE? What is the relationship of aggregates and transactions in aggregate-oriented databases? What is an offline lock? What is logical consistency? What is replication consistency? Is handling consistency a business choice? What is a network partition? In case of a network partition what does this imply for consistency and availability (following Fowler's explanation of CAP)? What is the trade-off between consistency and response time in a distributed system?Who should use NoSQL and what does that have to do with 64K?

0.2 History of Relational Databases
0.2.1 A Footnote about the Young History of Database Systems
Why would it make sense to use a database system anyway? How did it all start? What was a major change introduced by the relational model? What were major developments in database history?

0.2.2 Relational Database --- A Practical Foundation of Productivity
What was the problem with data management in the 60ies? What is associative addressing in the context of a database system? What is a data model? In the relational model, does the order of the columns in a schema matter? In the relational model, does the order of the rows in a schema matter? What is the primary goal of relational processing? Is relational algebra intended to be used as a language for end-users?
| Material | |
|---|---|
| Literature | |
1.2 Storage Media
1.2.1 Tape
What are the major properties of tape? Why would tape still be important these days? What is a tape jukebox? How does it work? What does this imply for access times?
| Additional Material | |
|---|---|
| Literature | |

1.2.2 Hard Disks, Sectors, Zone Bit Recording, Sectors vs Blocks, CHS, LBA, Sparing
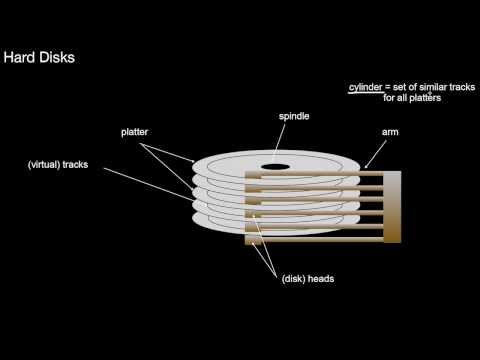
Why would hard disks still be important these days? What is a platter? What is a diskhead and a disk arm? How do tracks and cylinders relate? What is the difference of a circular sector from a HD sector? What is zone bit recording? What does this imply for sequential access? Where are self-correcting blocks used? What is the difference of HD sectors and operating systems blocks? What is physical cylinder/head/sector-addressing? What is logical cylinder/head/sector-addressing? How does it relate to the former? What is logical block addressing? What is sparing? What does this imply for sequential accesses?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |
| Video | |
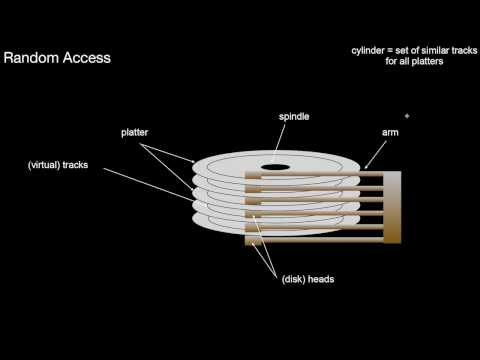
1.2.3 Hard Disks, Sequential Versus Random Access
What exactly is a random access? What are its major components? What is a sequential access? How to estimate the costs of a sequential access? What is track skewing? How did hard disks evolve over the last decades? What do we learn from that? Bonus Question: What does this imply for index structures?
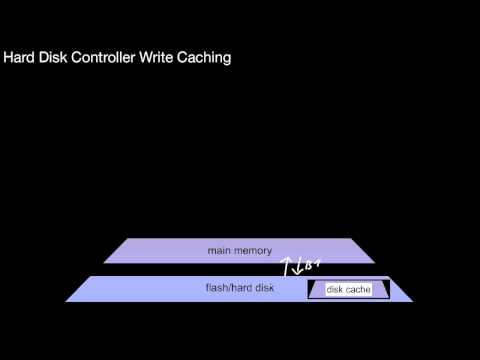
1.2.4 Hard Disks, Controller Caching
What exactly is the hard disk cache? How is it related to the storage hierarchy? What do we gain by using this cache? What do we lose? What does this imply when storing data on disk? What is the elevator optimization?
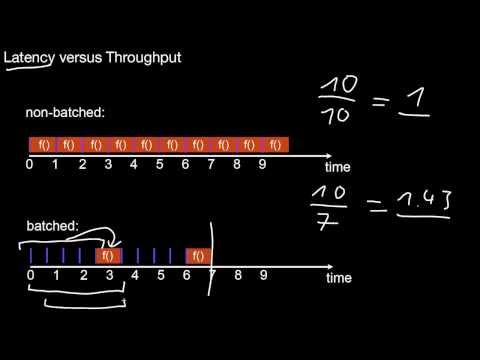
1.2.5 The Batch Pattern
What is the central observation here of the batch pattern? What are the advantages? What are the disadvantages? What does this mean for practical algorithms? What are possible applications?
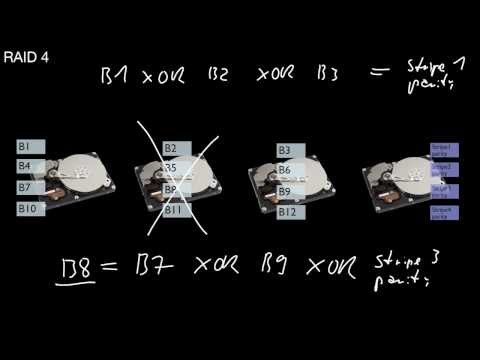
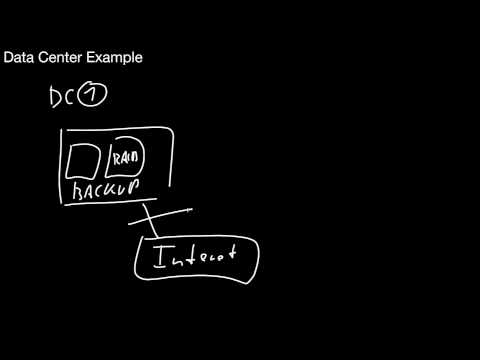
1.2.6 Hard Disk Failures and RAID 0, 1, 4, 5, 6
Why should I worry about hard disk failures? What is the core idea of RAID? What is the impact on performance of RAID 0? Is my data safer by using RAID 0? What RAID 1? How much space does it waste? What is the difference of RAID 4 and RAID 5? How many disks do I need for a RAID 4 or 5 system? Which sequential read performance can I expect in a system with n disks? And which write peformance? How many disk failures may a RAID 4 or 5 system survive? What is the difference of RAID 6 compared to RAID 5?
| Additional Material | |
|---|---|
| Literature |
|
| Further Reading | |
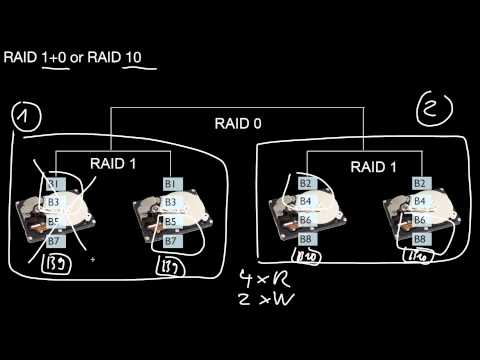
1.2.7 Nested RAID Levels 1+0, 10, 0+1, 01
What is RAID 10? Why would we call this nested RAID? And what is RAID 01 then? Is it possible, in principal, to combine any kinds of RAID-levels?
1.2.8 The Data Redundancy Pattern
Why is data redundancy good? And for what exactly? Why is data redundancy bad? And for what exactly? Can you list three examples where data redundancy is used for good?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |
1.2.9 Flash Memory and Solid State Drives (SSDs)
What are the major properties of flash devices? What is an SSD? What is the major differentiator over hard disks w.r.t. performance? In an SSD, what are blocks and superblocks? What does this mean for write operations? What is write amplification? How would this affect the storage layer of a database system? Why trim? What is the job of the SSD controller? How does it relate to RAID? How does it relate to volatile memory? Which sequential bandwidth can we expect these days? And which random access time?

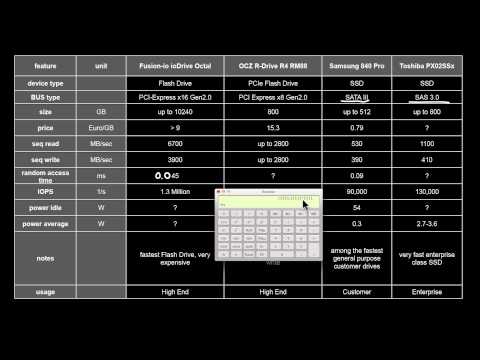
1.2.10 Example Hard Disks, SSDs and PCI-connected Flash Memory
Again, what are typical performance characteristics of hard disks and SSDs? Would you buy an SAS disk for your PC? What is a PCI flash drive? Why would that be a good idea? Why do I get considerably more random read operations per second than one divided by the random access time?
2.2 Page Organizations
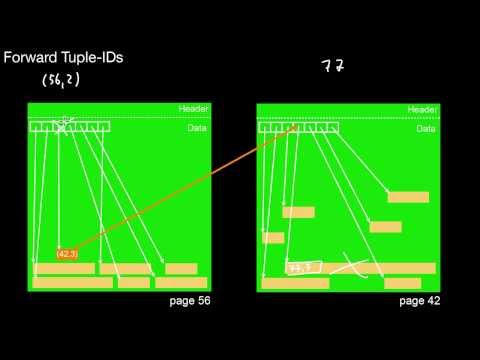
2.2.1 Slotted Pages: Basics
What is the core idea of slotted pages? What is a slot? What is the relationship to physical data independence? Can I move data inside a slotted page? Like how? What is a forward tuple-ID? What are they good for? What might be a problem?
| Additional Material | |
|---|---|
| Literature | |
2.2.2 Slotted Pages: Fixed-size versus Variable-size Components
How to organize fixed-size components on a slotted page? Where to store the slot array then? What is linear addressing? What can we do with variable-sized components? Can we move them around on a page?
| Additional Material | |
|---|---|
| Literature | |

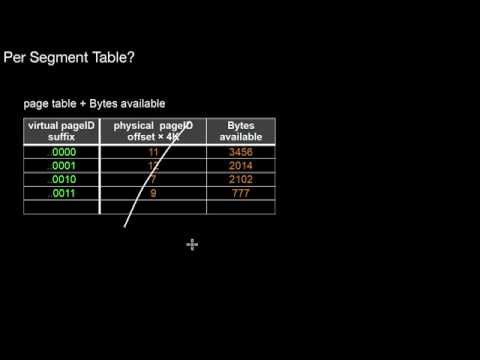
2.2.3 Finding Free Space
How would we find some free space for new stuff? What is a segment?
| Additional Material | |
|---|---|
| Literature | |
3.2 B-Trees
3.2.1 Three Reasons for Using B-Tree Indexes, Intuition, Properties, find(), ISAM, find_range()
The three reasons for using B-tree indexes are ... ? What is the intuition for B-tree indexes? What is a node? What is a leaf? How many keys do they have? What happens if the are root? What is k? What is k*? What are the major properties of a B-tree? What is the relationship of B-trees to interval partitioning? How do we search for a particular key in a B-tree, i.e. how do we execute a point query? How do we search for a particular interval in a B-tree, i.e. how do we execute a range query? What is the index sequential access method (ISAM)? How does it relate to point and range queries?
| Additional Material | |
|---|---|
| Literature |
|
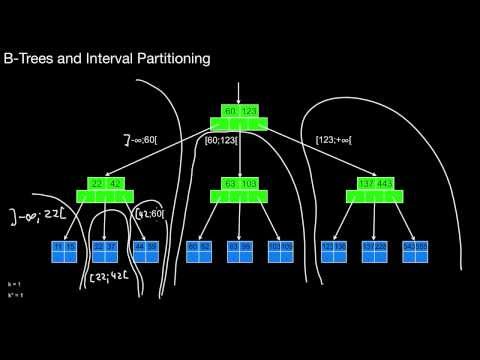
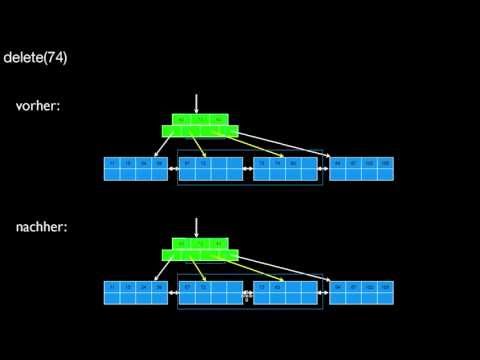
3.2.2 B-Tree insert, split, delete, merge
How do inserts in real B-trees work? Why would I split a leave or a node? And how does this split work in principal? How do I implement the split operation in an object-oriented programming language? What does this mean for leaf and node splits? How do I delete data from a B-tree and its leaves and nodes? What may happen then? How are delete() and insert() related? How are merge() and split() related?
| Additional Material | |
|---|---|
| Literature |
|

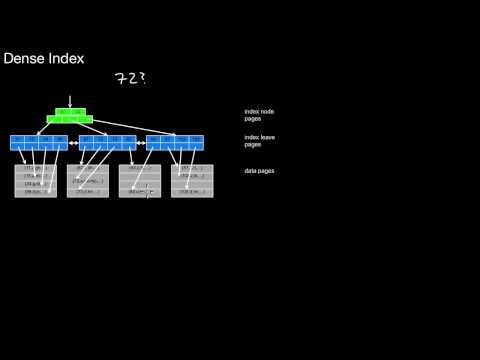
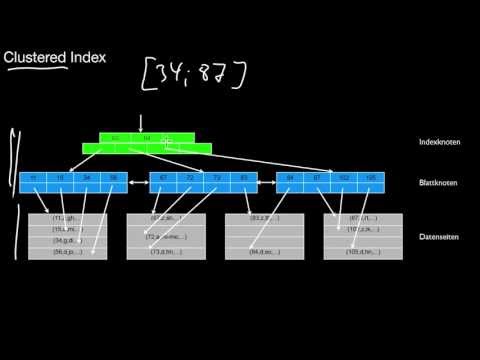
3.2.3 Clustered, Unclustered, Dense, Sparse, Coarse-Granular Index
What is a clustered index? How many clustered indexes are possible for a table? What is an unclustered index? How many unclustered indexes are possible for a table? What is a dense index? What is a sparse index? And how are they related? How is a coarse-granular index related to a sparse index? How is a sparse index related to having no index at all?
| Additional Material | |
|---|---|
| Literature |
|
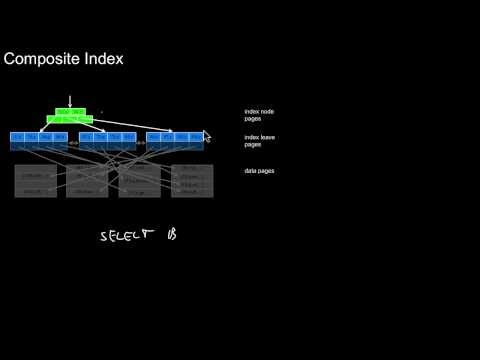
3.2.4 Covering and Composite Index, Duplicates, Overflow Pages, Composite Keys
How is a covering index related to an unclustered index? How is it related to a clustered index? What exactly is covered? What is a composite index? How does it relate to a covering index? How do we build a duplicate index in a B-tree ? What is an overflow page? How are composite keys related to duplicates?
| Additional Material | |
|---|---|
| Literature | |
3.2.5 Bulk-loading B-Trees or other Tree-structured Indexes
How do I bulkload a B-tree? And why would I want to do this? What should be kept in mind for the free space in nodes and leaves when bulkloading?
| Additional Material | |
|---|---|
| Literature | |

4.2 Implementing Grouping and Aggregation
Would it be fair to say that grouping and aggregation is just like co-grouping however using a single subset for each co-group? Which phases can be identified in hash-based grouping? What exactly is kept in the hashmap? Which phases can be identified in sort-based grouping? What is `group closing'? How to handle the last group?
| Additional Material | |
|---|---|
| Literature | |

5.2 Cost-based Optimization
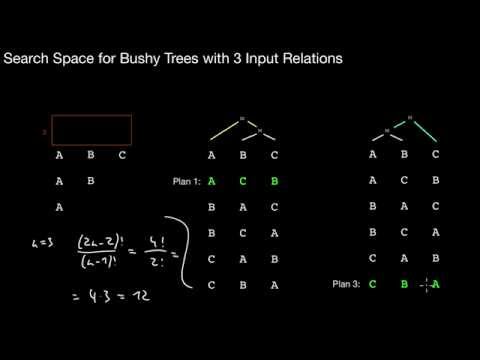
5.2.1 Cost-Based Optimization, Plan Enumeration, Search Space, Catalan Numbers, Identical Plans
Why is join order important? Which other binary operators may be affected by this problem? What is the overall idea in cost-based optimization? What is a left-deep tree? What is the number of possible left-deep plans for n input relations? What is a bushy tree? What is the number of possible bushy plans for n input relations? What do the Catalan numbers have to do with this? What is the assumption for the different plans when counting bushy plans?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |
5.2.2 Dynamic Programming: Core Idea, Requirements, Join Graph
What is the join graph? What is the core idea of dynamic programming? What are the two requirements such that dynamic programming makes sense? What is an optimal subplan?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |

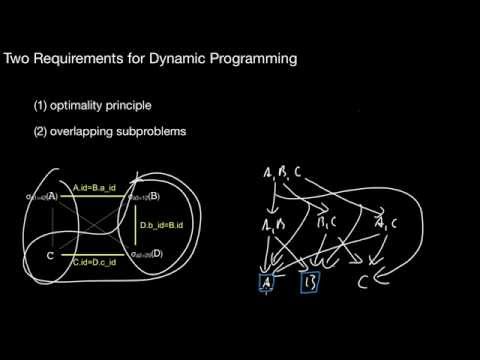
5.2.3 Dynamic Programming Example without Interesting Orders, Pseudo-Code
How does dynamic programming work in principle when applied to the join enumeration problem? What does the pruning step do? How many different entries does the table have at each iteration step? What does the mergePlan()-method do? How would it merge two subplans?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |

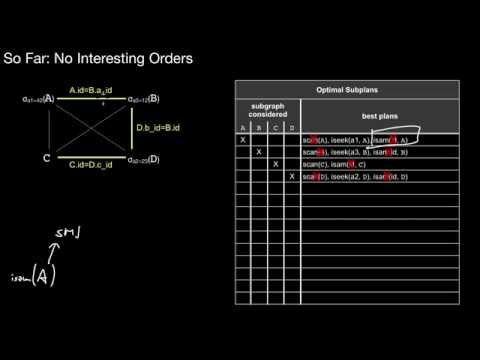
5.2.4 Dynamic Programming Optimizations: Interesting Orders, Graph Structure
What is an interesting order? Why do we have to change the simple dynamic programming algorithm to consider interesting orders? When exactly would we change the algorithm? Why would we exploit the join graph in dynamic programming? What effect does this have?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |
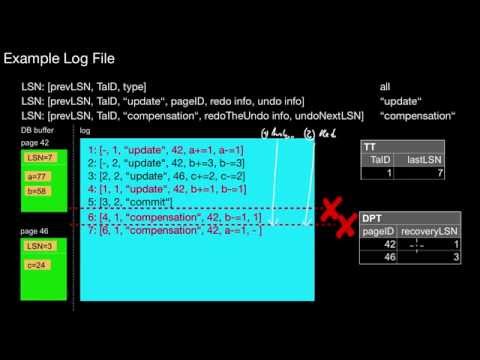
6.2 ARIES
What are the three phases of ARIES? What is the purpose of the transaction table (TT)? What is the lastLSN? What is the purpose of the dirty page table (DPT)? What is the recoveryLSN? Which assumptions do we make in ARIES-recovery? What information is contained in a log record? In any log record? In update log records? What is the redo information and undo information? What is the relationship of LSNs and database pages in the store? How is TT maintained during logging? How is DPT maintained during logging? What is the general idea of a compensation log record (CLR)? What is the redoTheUndo information contained in it? Where does undoNextLSN point to? How do we shorten (prune) a log file? How do we shorten the analysis phase? How do we shorten the redo phase? How do we shorten the undo phase? How do we determine firstLSN? Where do we cut-off the log? How exactly is a fuzzy checkpoint written to the log file? What are the core tasks of the three phases of ARIES? What does `repeating history' mean in this context?
| Material | |
|---|---|
| Literature | |
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |

7.2 Introduction to Big Data
What is big data? What are applications of big data? What are volume, variety, velocity, and veracity? What do they mean? Is big data always big?

1.3 Fundamentals of Reading and Writing in a Storage Hierarchy
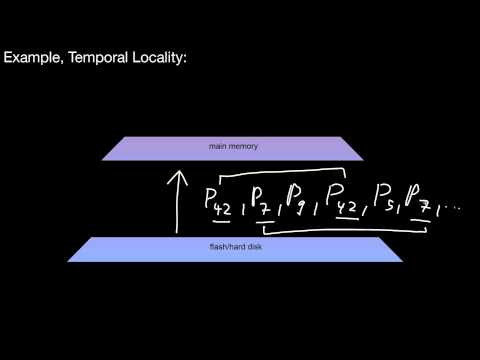
1.3.1 Pulling Up and Pushing Down Data, Database Buffer, Blocks, Spatial vs Temporal Locality
What does pulling up data mean? What does pushing down data mean? Did you see the database buffer anywhere? What is temporal locality? And what is spatial locality then? How are the two related?
| Material | |
|---|---|
| Literature | |
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |
1.3.2 Methods of the Database Buffer, Costs, Implementation of GET
What are the most important methods of the database buffer? What does GET do? What may happen when requesting a page that is not in the buffer? What are the costs involved? Who would evict a page?

1.3.3 Pushing Down Data in the Storage Hierarchy (aka Writing), update in-place, deferred update
What is direct write? What is indirect write? What are their pros and cons?

1.3.4 Twin Block, Fragmentation
What is the core idea of twin block? What are its pros and cons?
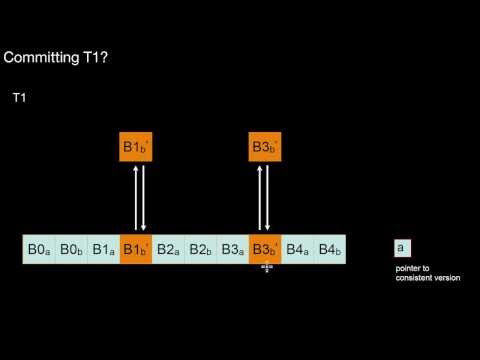
1.3.5 Shadow Storage
What is the core idea of shadow storage? What are its pros and cons? What about fragmentation in shadow storage? Where is this used outside databases?
1.3.6 The Copy On Write Pattern (COW)
When is this pattern applicable? What is the core idea? Where is it applied?

1.3.7 The Merge on Write Pattern
When is this pattern applicable? What is the core idea? Where is it applied? What is the relationship to COW?
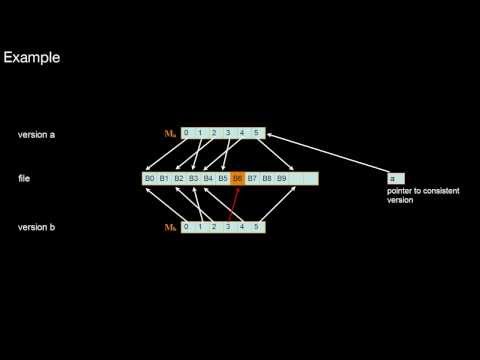
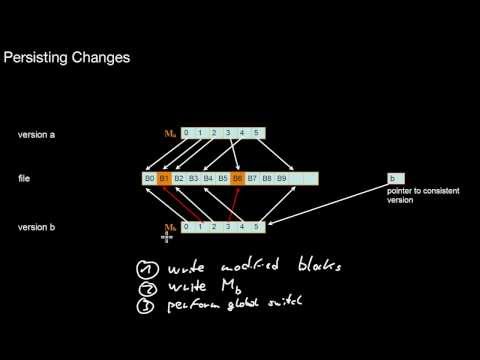
1.3.8 Differential Files, Merging Differential Files
What is the main analogy from real life for differential files? To which other patterns does this relate? What are its pros and cons? How to merge differential files with the read-only DB without halting the database?

1.3.9 Logged Writes, Differential Files vs Logging
What is the difference of logging and differential files? What are its pros and cons? Is it possible to combine logging and differential files?

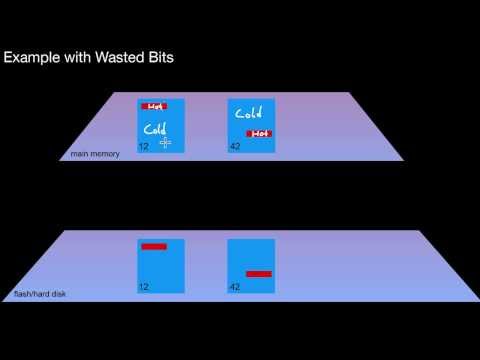
1.3.10 The No Bits Left Behind Pattern
Why shouldn't we leave any bits behind? Or in other words: why should we avoid wasting bits? What does this mean for data layouts? Why would I cluster data with spatial locality on the same virtual memory page, disk page, disk sector, cache line? Why would I keep data with little spatial locality on different virtual memory pages, disk pages, disk sectors, cache lines?
2.3 Table Layouts
2.3.1 Data Layouts: Row Layout vs Column Layout
Why would we linearize data values in row layout? Why would we linearize data values in column layout? Which type of layout is better for which type of query? What is a row store? What is a column store?

2.3.2 Options for Column Layouts, Explicit vs Implicit key, Tuple Reconstruction Joins
What are correlated columns? Could they also be uncorrelated? And what would that imply? What is an implicit key? What does this mean for tuple reconstruction joins? What is an explicit key? What does this mean for tuple reconstruction joins? How do I get from explicit key to implicit key?

2.3.3 Fractured Mirrors, (Redundant) Column Grouping, Vertical Partitioning, Bell Numbers
What is the relationship of fractured mirrors to row and column layouts? Why would this make sense? This is good for which type of queries again? What are the drawbacks? What is column grouping and its relationship to vertical partitioning? Which type of queries would benefit from this? How would we introduce data redundancy to column grouping? How many vertical partitionings are there? What has this to do with The Data Redundancy Pattern?
| Additional Material | |
|---|---|
| Literature | |

2.3.4 PAX, How to choose the optimal layout?
What is PAX about? How does this relate to horizontal partitioning? How does the horizontal partitioning relate to blocks? How does PAX relate to column layouts? What would this be good for? And how do I get to the optimal data layout anyway?
| Additional Material | |
|---|---|
| Literature | |

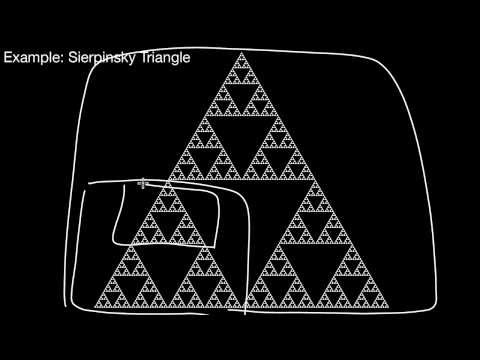
2.3.5 The Fractal Design Pattern
What is fractal (self-similar) design about in the context of database sytems? Why would this help me to devise effective solutions to problems? How does this relate to The All Levely are Equal Pattern? Can you name a couple of examples of fractal design in databases that we have already seen?
3.3 Performance Measurements in Computer Science
How to determine which algorithm, index, or whatever is better? O-Notation is good enough, right? What are the three ways to measure the performance of a computer program? What is asymptotic complexity? What is a cost model? What is a simulation? What might be the problem of all of the former methods? What is an experiment? What could be its problem? How are the three ways to measure the performance of a computer program correlated to effort/cost, reality, and generalizability?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |
4.3 External Sorting
4.3.1 External Merge Sort
When does it make sense to run external merge sort? What is run generation? How does it work? What is the result of it? What happens during the merge phase, i.e. pass > 0? What happens during a single merge? What is the fan-in F? How could it be defined? Why would it be a bad idea to implement merge sort with a fan-in of F=2? Why would it also be a bad idea to implement merge sort with a fan-in F=m-1 (where m is the number of pages available in main memory)? How are the different runs organized in main memory? What exactly is stored for each run? Which runs are typically merged first? You did not forget that this specific variant is a very simple version of the algorithm, right?
| Additional Material | |
|---|---|
| Literature | |
| Video | |

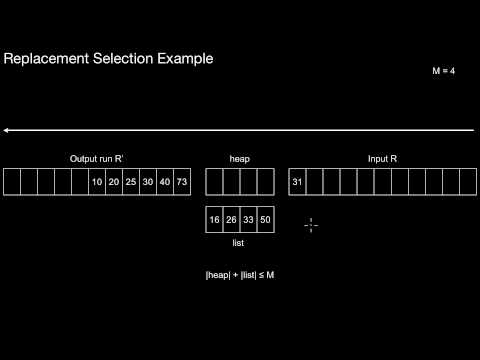
4.3.2 Replacement Selection
Which overall impact does Replacement Selection typically have when used with External Merge Sort? What is the typical size of a run generated by Replacement Selection compared to Quicksort? What is the purpose of the heap and the list? How are they implemented physically? Which condition must hold at all times for the list and the heap? How does the algorithm start? What is the central idea then? When is an element inserted into the heap? When is it inserted into the list? When does a run end? What can be said about the cache-efficiency of this algorithm?
4.3.3 Late, Online, and Early Grouping with Aggregation
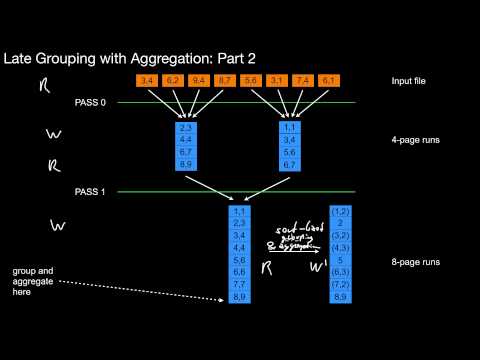
What is late aggregation? What is the amount of I/O you can expect then? What is online grouping? Can this only be used with grouping? What do you gain in terms of I/O? What is early aggregation? What do you gain in terms of I/O? What are drawbacks of both Online and Early Grouping? What has a huge impact on the actual savings for Early Grouping?
5.3 Query Execution Models
5.3.1 Query Execution Models, Function Calls vs Pipelining, Pipeline Breakers
How to execute a plan? How to translate a plan to an executable plan? Why not use function libraries? What is the problem with intermediate results? What is the core idea of pipelining? What type of pipelining are we talking about here? What is a pipeline breaker? And why would that matter in query processing? What are the three stages of simple hash join/index nested-loop join? What happens in each stage? What are the three stages of quicksort? What happens in each stage? What are the three stages of external merge sort? What happens in each stage? For all of these algorithms: which of those stages actually block the pipeline? What are the blocking and non-blocking building blocks of query pipelines?
| Additional Material | |
|---|---|
| Literature | |
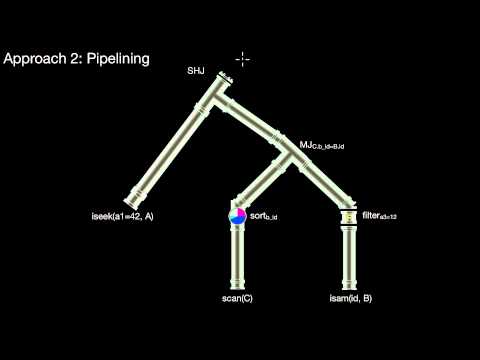
5.3.2 Implementing Pipelines, Operators, Iterators, ResultSet-style Iteration, Iteration Granularities
How do we implement a pipeline, i.e. how do we get from the high-level idea of pipelining to a concrete implementation of pipelining? What is the core idea of the operator interface? What's next()? What happens in a hasNext()-call in an iterator? What is a chunk? Which important special cases of chunks are important? What would be a simple, textbook-style, translation of a plan using operators? What is ResultSet-style iteration? Is this restricted to rows or can we use it for columns as well? Would it make sense to iterate over pages?
| Additional Material | |
|---|---|
| Literature | |
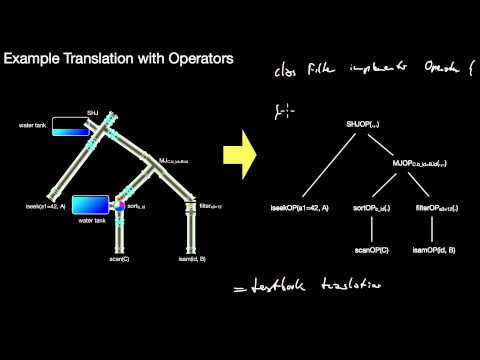
5.3.3 Operator Example Implementations
How do we implement specific operators without unnecessarily breaking the pipeline? Is it hard to implement a projection or selection operator? How do we handle loops in operator implementations? What do we mean by `state' here?
| Additional Material | |
|---|---|
| Literature | |

5.3.4 Query Compilation
What is the performance problem with operators? How is the pipeline organized when compiling code? How do algebraic expressions translate into code? How to translate entire plans into LLVM/C++ code?
| Material | |
|---|---|
| Literature | |
| Additional Material | |
|---|---|
| Literature | |
| Code Example | |
| Code Example Slides | |
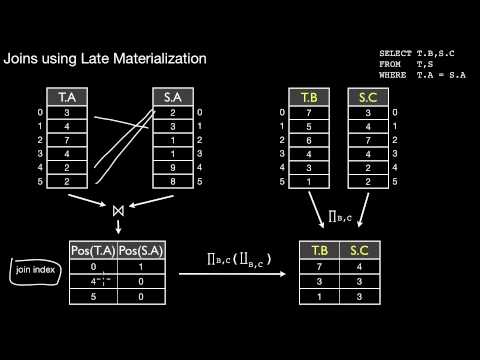
5.3.5 Anti-Projection, Tuple Reconstruction, Early and Late Materialization
What is early materialization? What is the relationship to column and vertically partitioned (column grouped) layouts? How would we do early materialization partially? What is an anti-projection? How could we implement early materialization in a column store? How could we implement late materialization in a column store? What is the impact on join processing? What is a join index? What is the impact on query planning?
7.3 Introduction and Recap of MapReduce
What are the three different MapReduces? What are the semantics of the map() and reduce()-functions? What are the different types of Hadoop? What is HDFS? How is data stored on HDFS? How is a file partitioned and replicated? To which RAID-level does this correspond? Why would partitioning help for load balancing? What are the three phases of MapReduce? What is a mapper? What is a split? Where is the output of the map()-calls stored? Is the data of all copies mapped in the map phase? What does the shuffle phase do? How could that be described in SQL? On what data is reduce() called? Where is the result of the reduce phase stored?
| Additional Material | |
|---|---|
| Literature |
|
| Additional Recap Material (from undergrad lecture, in German) | |
|---|---|
| Literature | |
| Video | |
| Slides |
|
1.4 Virtual Memory
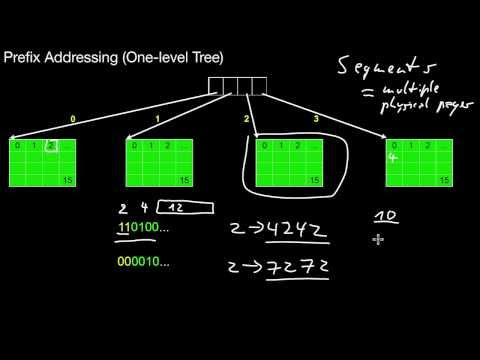
1.4.1 Virtual Memory Management, Page Table, Prefix Addressing
How are virtual memory addresses translated to physical addresses? How does it work? What is the role of the page table? What is prefix addressing?
| Additional Material | |
|---|---|
| Literature | |
1.4.2 Retrieving Memory Addresses, TLB
What happens when referencing a specific virtual memory address? What kind of translation lookaside buffer (TLB) and cache misses may occur?
| Additional Material | |
|---|---|
| Literature | |

2.4 Compression
2.4.1 Benefits of Compression in a Database, Lightweight Compression, Compression Granularities
Compression is mainly about saving storage space, right? But wait: wasn't there something more important? What is the major trade-off you have to keep in mind here? Compressing data costs something in addition! You can only lose w.r.t. overall query response times, right? What are compression granularities? How do they affect accessibility and compression ratio of your data (in general)?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |

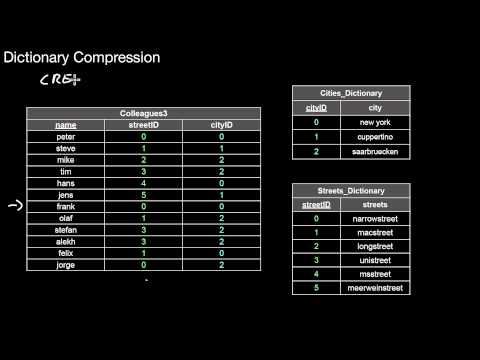
2.4.2 Dictionary Compression, Domain Encoding
What is a dictionary? What do we gain by using one? How does this relate to CREATE DOMAIN? How would dictionaries affect query processing? Is a dictionary something a user has to be aware of? How does dictionary compression relate to domain encoding? What are the pros and cons of dictionary compression?
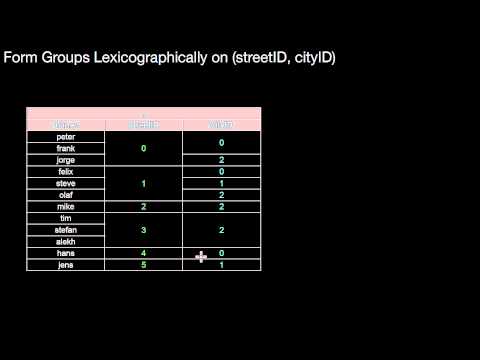
2.4.3 Run Length Encoding (RLE)
How does run length encoding method work? What is its relationship to sorting? To lexicographical sorting? What might be possible pros and cons?
2.4.4 7Bit Encoding
What is the major idea of this method? How would this relate to domain encoding? How much storage space do I lose? How much do I gain?
| Additional Material | |
|---|---|
| Further Reading | |

3.4 Static Hashing, Array vs Hash, Collisions, Overflow Chains, Rehash
Why do some people say that the three most important techniques in computer science are hashing, hashing, and hashing? What is the core idea of hashing? What is the runtime complexity? How does it relate to arrays? What is a collision? How can I handle it? Why would I rehash? And what does that mean?
| Additional Material | |
|---|---|
| Literature |
|
| Further Reading | |

3.5 Bitmaps
3.5.1 Value Bitmaps
What is the core idea of a bitmap? What is a bitlist? What is the size of an uncompressed bitmap? What are typical bitmap operations and why are they very efficient? How is the cardinality of a domain related to the size of the bitmap? What are applications of bitmaps?
| Additional Material | |
|---|---|
| Literature | |
| Further Reading | |
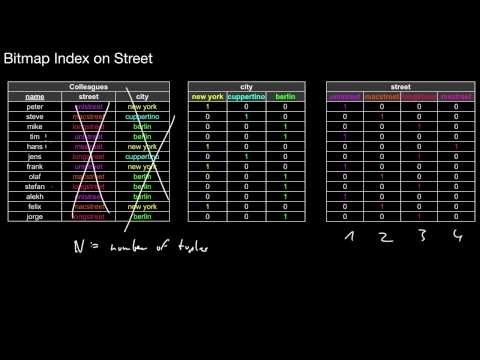
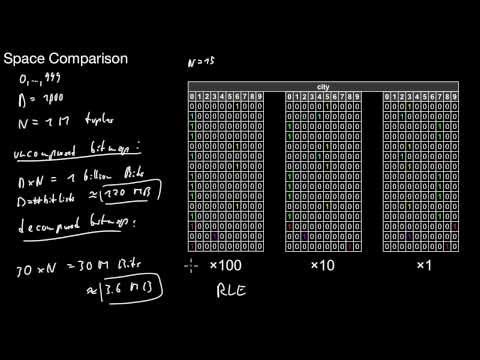
3.5.2 Decomposed Bitmaps
When does a decomposed bitmap make sense? What is the core idea of a decomposed bitmap? What does this imply for bitmap operations? What do we gain in terms of storage space?
3.5.3 Word-Aligned Hybrid Bitmaps (WAH)
What is the relationship of word-aligned hybrid bitmap WAH to 7-Bit and RLE? How does WAH work? How can we use this to compress a bitlist? How do we decompress?
| Additional Material | |
|---|---|
| Further Reading | |
| Java Libary | |

3.5.4 Range-Encoded Bitmaps
What is a range-encoded bitmap? What changes over the standard uncompressed bitmap? Which type of queries can be efficiently supported by range-encoded bitmaps? Can we also execute a point query? How exactly? What are the space requirements when compared to the standard uncompressed bitmap?

3.5.5 Approximate Bitmaps, Bloom Filters
What is the core idea of a bloom filter? When can it be applied? What is a false positive? What are the lookup semantics of a bloom filter?
| Material | |
|---|---|
| Literature | |
| Additional Material | |
|---|---|
| Literature | |
0 Einführung
Welche Themen werden in dieser Vorlesung behandelt? Welche Termine und administrativen Randbediungungen gibt es? Was ist eine Studienarbeit? Welche Literatur ist geeignet zum Nacharbeiten und wo finde ich sie?
| Zusätzliches Material | |
|---|---|
| Literatur | |

1.1 Warum Datenbanksysteme?
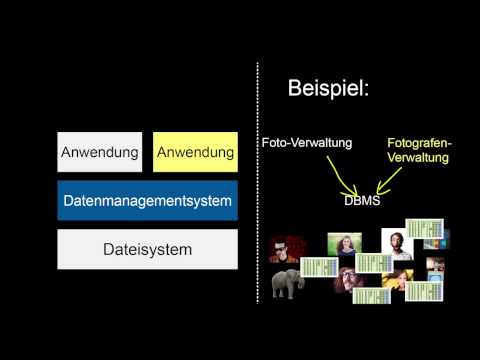
Welche Vor- und Nachteile haben Datenbanksysteme gegenüber Dateisystemen? Welche Abstraktionsebenen sind dabei entscheidend? Was sind Metadaten? Wann sollte ich ein Datenbanksystem benutzen und wann nicht? Wann sollte ich Daten lieber direkt auf dem Dateisystem speichern? Wann sollte ich ein Datenbanksystem einsetzen und wann nicht? Was bedeutet das für den Aufwand?
| Zusätzliches Material | |
|---|---|
| Literatur | |
2.1 Grundlagen, Funktionalitäten, Rollen, Rekursion
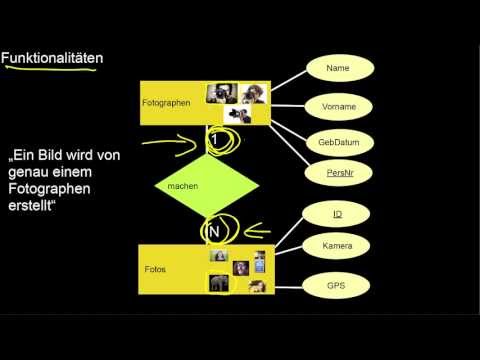
Was sind Entitätstypen und Entitäten? Was sind Beziehungstypen und was sind Beziehungen? Was sind Attribute? Wie darf ich die verschiedenen Modellierungselemente verbinden? Was ist ein Schlüssel? Und wie wird er markiert? Welche Anforderungen sollte er erfüllen? Was sind Funktionalitäten? Welche Art von Funktionalitäten gibt es für zweistellige Beziehungstypen? Wie notiere ich das? Wie lese ich das? Was genau schränken diese Funktionalitäten ein und was nicht? Wie ist die Leserichtung in ER? Was ist eine Rolle? Warum ist die Rekursion hier nicht gleich der Rekursion aus Programmiersprachen? Was genau modelliert Rekursion? Was genau schränkt Rekursion ein und was nicht? Wie hängen Rollen und Rekursion zusammen?
| Zusätzliches Material | |
|---|---|
| Literatur | |
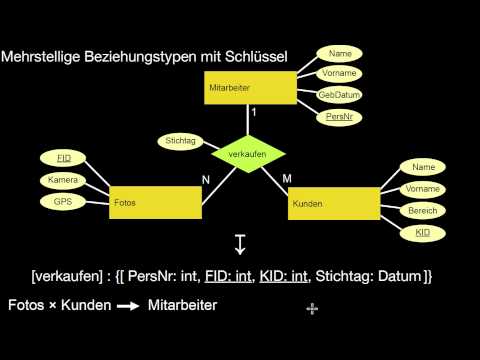
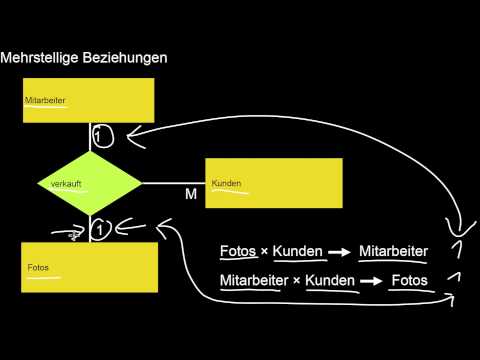
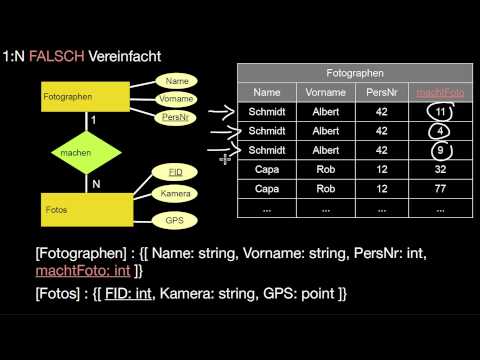
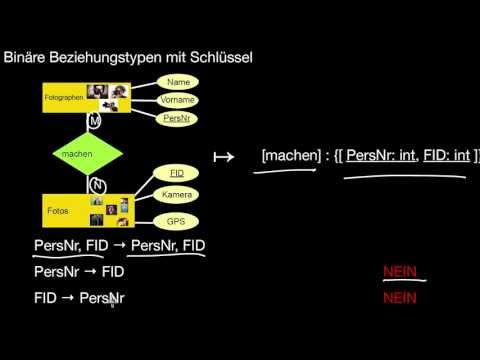
4.1 Grundlagen, binäre und mehrstellige Beziehungstypen
Wie erfolgt die Übersetzung eines E/R-Modells zum Relationalen Modell? Wie übersetze ich Entitätstypen? Wie übersetze ich Beziehungstypen? Was passiert jeweils mit den Attributen und Schlüsseln? Wie übersetze ich mehrstellige Beziehungstypen? Welche Optionen habe ich dabei in welcher Situation? Was kann bei dieser Übersetzung an Information verloren gehen? Und wie stelle ich sicher, dass nichts verloren geht?
| Zusätzliches Material | |
|---|---|
| Literatur | |
5.1 Relationen versus Tabellen
Wie unterscheiden sich Relationen von Tabellen? Welche zwei Eigenschaften haben Tabellen, die Relationen nicht haben und warum? Was bedeutet das für die Elemente in einer Relation bzw. in einer Tabelle? Was wird in einem Datenbanksystem verwaltet: Relationen oder Tabellen?

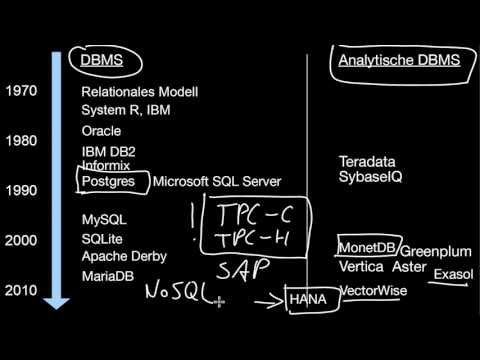
6.1 Übersicht über Datenbanksysteme: Welches DBMS für was?
Welche Datenbanksysteme (DBMS) gibt es eigentlich? Welches DBMS ist gut für was? Wie unterscheiden sich DBMS von Analytischen DBMS? Welche Benchmarks geben Hinweise auf die wirkliche Leistung eines DBMS?
| Zusätzliches Material | |
|---|---|
| Literatur | |
7.1 SQL Standards und Teilsprachen
Welche verschiedenen SQL-Standards gibt es? Was für SQL-Teilsprachen muss ich kennen?
| Zusätzliches Material | |
|---|---|
| Literatur | |


8.1 Tabellendefinition
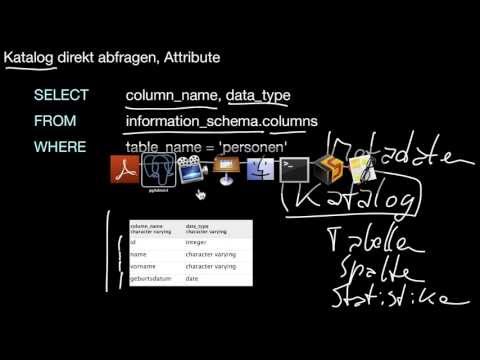
8.1.1 Grundlagen
Wie lege ich eine Tabelle in SQL an? Wie ändere ich ihre Definition? Was ist der Datenbankkatalog? Wie lösche ich Tabellen? Wie erhalte ich Informationen über die Tabellendefinition? Was ist die psql-Shell?
| Zusätzliches Material | |
|---|---|
| Literatur | |
8.1.2 Datentypen
Was für Datentypen stehen hierfür zur Verfügung? Was ist numeric? Was ist varchar?
| Zusätzliches Material | |
|---|---|
| Literatur | |

8.1.3 Schlüssel
Wie definiere ich Primärschlüssel, Schlüssel, Fremdschlüssel und einfache Integritätsbedingungen? Was ist ein CONSTRAINT? Wie kann ich Kandidatenschlüssel markieren? Wie deklariere ich Referenzen auf andere Tabellen? Und wieso eigentlich? Wie unterscheidet sich FOREIGN KEY von REFERENCES und dieses wiederum von CONSTRAINT?
| Zusätzliches Material | |
|---|---|
| Literatur | |
| Presse | |

8.1.4 Weitere Einschränkungen des Schemas
Wie erzwinge ich Definiertheit von Werten oder lege mir selbst einen Datentyp an? Was ist der Unterschied von PRIMARY KEY und UNIQUE NOT NULL? Wie lege ich Default-Werte für neue Einträge fest? Wie kann ich überprüfen, ob neue Werte in bestimmten Bereichen liegen? Wie lege ich Unteranfragen innerhalb einer CHECK-Klausel an? Wie kann ich eigene Datentypen erzeugen? Wie ist der Zusammenhang zwischen DOMAINs, Dictionaries und Fremdschlüsseln? Wie verwende ich eine DOMAIN?
| Zusätzliches Material | |
|---|---|
| Literatur | |
9.1 Trigger
9.1.1 Grundlagen
Was macht ein Trigger prinzipiell? Wie lege ich ihn an?
| Zusätzliches Material | |
|---|---|
| Literatur | |

9.1.2 Details
Für welche Art der Änderungsoperation wird ein Trigger ausgelöst? Für welche Granularität von Ereignissen wird der Trigger ausgelöst? Zu welchem Zeitpunkt wird der Trigger ausgelöst? Wenn es mehrere Trigger auf einer Tabelle gibt: wann wird welcher Trigger ausgelöst? Für was sollten Trigger verwendet werden? Was sind die Nachteile von Triggern? Was sind die Vorteile?
| Zusätzliches Material | |
|---|---|
| Literatur | |

9.1.3 Konsistenztrigger
Wie kann ich Trigger einsetzen, um die Konsistenz meiner Datenbank sicherzustellen? Was ist Atomicity und Consistency? Was ist eine Transaktion? Und was bedeutet dies für Trigger? Was genau wird für ein INSERT, DELETE oder UPDATE ausgeführt, wenn es Trigger für dieses INSERT, DELETE oder UPDATE gibt? Und was nicht? Wie kann ich die Überprüfung von Fremdschlüsselbeziehungen an das Ende einer Transaktion verschieben? Wie kann ich die Ausführung des Triggers an das Ende einer Transaktion verschieben?
| Zusätzliches Material | |
|---|---|
| Literatur | |

11.1 Was ist eigentlich NoSQL?
Was ist mit NoSQL wortwörtlich gemeint? Welche Klassen von NoSQL-Systemen gibt es? Welche Systeme machen wann überhaupt Sinn? Und wieso sollte ich in vielen Fällen dann lieber doch ein SQL-DBMS benutzen? Was ist Hadoop MapReduce? Was ist ein Key-Value Store? Was ist ein Column Store?
| Zusätzliches Material | |
|---|---|
| Literatur | |

10.1 Schemadesign
Was ist schlechtes Schemadesign? Warum ist das überhaupt ein Problem? Warum kann das in einem Software-Projekt (sehr) teuer werden? Was ist Datenredundanz? Was sind Änderungsanomalien? Was sind Einfügeanomalien? Was sind NULL-Werte? Wofür stehen NULL-Werte? Und wieso sind zuviele davon garnicht gut? Was sind Löschanomalien? Was sind unechte Tupel/Daten?
| Zusätzliches Material | |
|---|---|
| Literatur | |
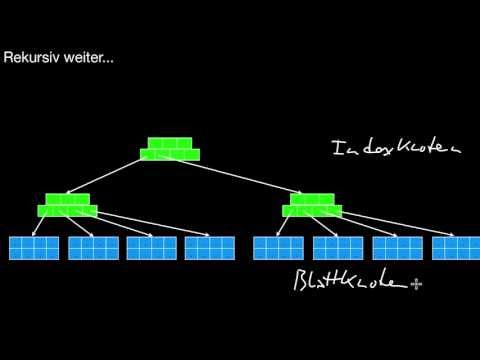
12 B-Bäume
Was ist die Grundidee eines Index? Wie unterscheiden sich Indexe von Karteikästen? Was ist eine Seite? Wie unterscheiden sich B-Bäume von binären Suchbäumen? Sind B-Baum und B^+-Baum eigentlich dasselbe? Wie suche ich Daten in einem B-Baum? Wieso werden Bereichsanfragen auf Schlüsseln gut unterstützt? Was ist ISAM? Wie füge ich effizient ein? Wie genau funktioniert split() prinzipiell? Und wie genau implementiere ich das? Was ist der Unterschied zwischen einem Clustered und einem Unclustered B-Baum? Und wann macht welcher von beiden Sinn? Welche und wieviele dieser Indexe kann ich für eine Tabelle erstellen? (Und wieso hat PostgreSQL keinen Clustered Index ;-)?)
| Zusätzliches Material | |
|---|---|
| Literatur | |
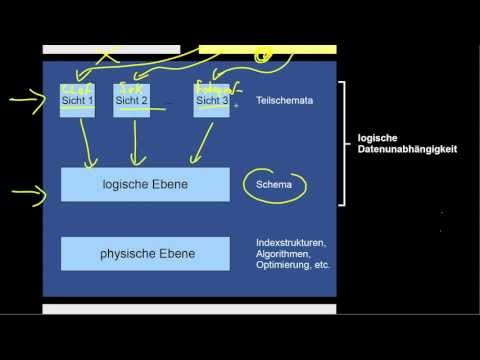
1.2 Physische und Logische Datenunabhängigkeit
Was sind physische (PDUA) und logische Datenunabhängigkeit (LDUA)? Was ist die physische Ebene? Was ist die logische Ebene? Wozu braucht man diese Ebenen überhaupt? Was ist eine Sicht? Was sind die Gemeinsamkeiten von PDUA und LDUA und warum sind sie letztendlich Spezialfälle derselben Idee?
| Zusätzliches Material | |
|---|---|
| Literatur | |
2.2 Chen versus min/max, mehrstellige Beziehungstypen
Wie unterscheidet sich die Chen-Notation von min/max? Wie unterscheiden sich die beiden Notationen bezüglich ihrer Leserichtung? Was schränkt min/max ein, was Chen nicht einschränkt? Wozu braucht man mehrstellige Beziehungstypen? Wie funktionieren die beiden Notationen für mehrstellige Beziehungstypen? Wie werden die Notationen für mehrstellige Beziehungstypen gelesen? Was ist der Zusammenhang von Chen mit partiellen Funktionen?
| Zusätzliches Material | |
|---|---|
| Literatur | |
4.2 Zusammenfassen von Relationen
Wie fasse ich Relationen zusammen? Wann darf ich das und wann nicht? Was kann (und darf aber nicht) dabei schiefgehen? Welche Funktionalitäten werden wie übersetzt? Was ist bei 1:1-Beziehungstypen zu beachten?
| Zusätzliches Material | |
|---|---|
| Literatur | |
5.2 Basisoperatoren: Selektion, Projektion, Vereinigung, Differenz, Kreuzprodukt, Umbenennung
Wie kann ich Daten filtern und auswählen? Wie erzeuge ich eine Teilrelation mit bestimmten Eigenschaften? Wie erzeuge ich eine Teilrelation mit einer Untermenge der Attribute? Wieviele Tupel enthält das Ergebnis einer Projektion? Wann darf ich zwei Relationen vereinigen und wie ist das Ergebnis definiert? Wann darf ich zwei Relationen voneinander abziehen und wie ist das Ergebnis definiert? Was berechnet das Kreuzprodukt? Und wie groß ist es? Welche Arten von Umbenennung gibt es? Wann macht eine Umbenennung Sinn? Was sind die Basisoperatoren der relationalen Algebra?
| Zusätzliches Material | |
|---|---|
| Literatur | |

6.2 Postgres Installieren
Wie installiere ich PostgreSQL?
| Zusätzliches Material | |
|---|---|
| Literatur | |
7.2 Grundlagen
7.2.1 SELECT FROM WHERE
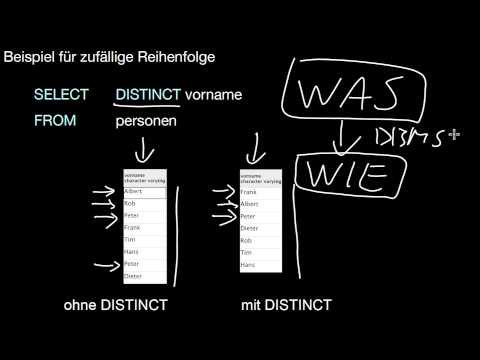
Was sind die Grundelemente einer SQL-Anfrage? Wie drücke ich Anfragen aus Relationaler Algebra in SQL aus? Wie berechne ich das Kreuzprodukt? Wie Selektion und Projektion? Was ist die konzeptuelle Ausführungsreihenfolge einer SQL-Anfrage? Wie unterscheidet sich das Ergebnis einer Anfrage in SQL von der in relationaler Algebra? Wie funktioniert SELECT und wofür wird es aufgerufen? Was bewirkt DISTINCT?
| Zusätzliches Material | |
|---|---|
| Literatur | |
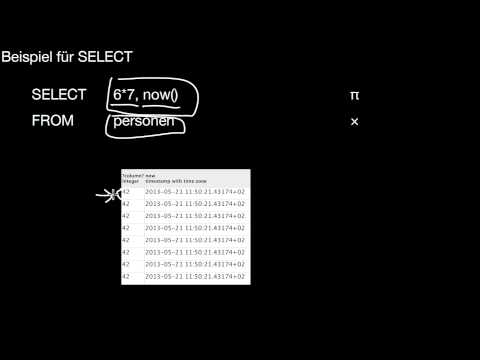
7.2.2 ORDER BY
Wovon hängt die Reihenfolge der Tupel im Ergebnis einer Anfrage ab? Wie kann ich das Ergebnis einer Anfrage sortieren? Nach welchen Kriterien?
| Zusätzliches Material | |
|---|---|
| Literatur | |
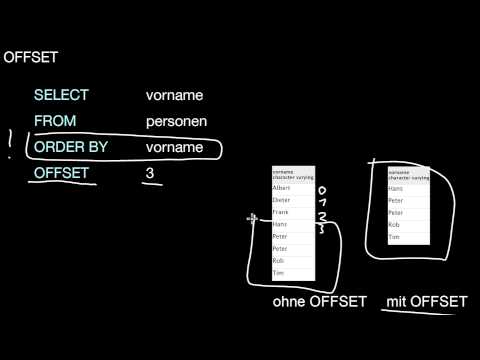
7.2.3 LIMIT
Wie kann ich die Anzahl der Ergebnisse einer Anfrage begrenzen? Wann macht das überhaupt Sinn?
| Zusätzliches Material | |
|---|---|
| Literatur | |
7.2.4 LIKE
Wie suche ich nach Teilen von Zeichenketten oder mit Wildcards?
| Zusätzliches Material | |
|---|---|
| Literatur | |

8.2 Datenmanipulation und Integritätsbedingungen
Was ist die Datenmanipulationssprache (DML)? Wie füge ich Tupel ein, ändere oder lösche sie? Was ist VALUES? Wie kann ich mit Hilfe einer Anfrage Daten einfügen? Welche Rolle spielt die Ausführungsreihenfolge bei UPDATE? Wie werden konzeptuell alle Änderungen durchgeführt?
| Zusätzliches Material | |
|---|---|
| Literatur | |

9.2 Regeln
Was macht eine Regel? Wie definiere ich eine Regel? Wie kann ich in PostgreSQL Sichten zum Schreiben freischalten? Was bedeutet dies für die Implementierung Logischer Datenunabhängigkeit? Wie unterschieden sich Regeln von Triggern?
| Zusätzliches Material | |
|---|---|
| Literatur | |

10.2 Funktionale Abhängigkeiten, Functional Dependencies (FD)
Was sind funktionale Abhängigkeiten? Wie erkenne ich sie? Und wie erkenne ich sie nicht? Was ist der Unterschied zwischen funktionalen Abhängigkeiten einer Ausprägung versus einer beliebigen Ausprägung (und damit des Relationenschemas)?
| Zusätzliches Material | |
|---|---|
| Literatur | |
11.2 MapReduce
11.2.1 Grundlagen
Wie ist die Semantik der map()- und der reduce()-Funktion? Wie erzeuge ich einen Web-Index mit map()- und reduce()-Funktionen? Wie setzte ich einfache SQL-Anfrage nach map() und reduce() um?
| Zusätzliches Material | |
|---|---|
| Literatur | |

11.2.2 Architektur
Was sind die wesentlichen Gemeinsamkeiten und Unterschiede der Architektur eines MapReduce-Systems zu einem DBMS?
| Zusätzliches Material | |
|---|---|
| Literatur | |
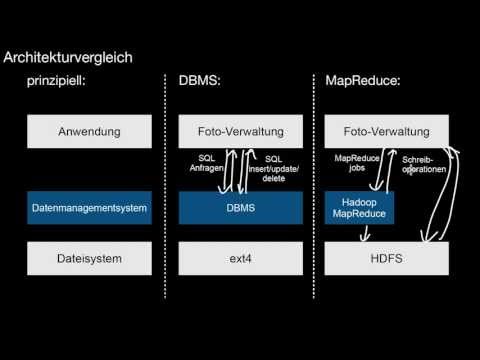
11.2.3 Verarbeitung auf einem Cluster
Wie wird ein MapReduce-Job prinzipiell verarbeitet? Und wie funktioniert dies auf einem großen Cluster? Was ist HDFS?
| Zusätzliches Material | |
|---|---|
| Literatur | |
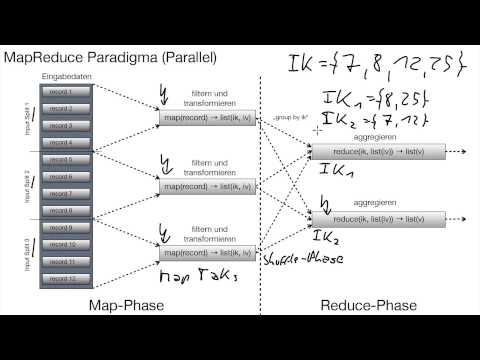
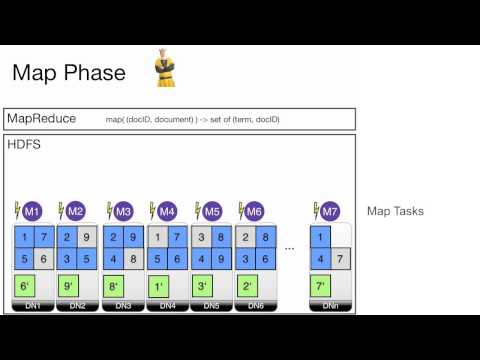
11.2.4 HDFS und Hadoop
Wie wird eine Datei intern von HDFS verarbeitet? Was ist eine Horizontale Partition? Was bedeutet dies für Failover und Lastbalancierung? Was ist Hadoop? Was passiert in der Map-Phase, Shuffle-Phase und Reduce-Phase? Was ist ein Map Task? Was ist ein Reduce Task? Was ist Redundanz in HDFS? Was bedeutet dies für Failover und Lastbalancierung? Was ist eine Intervall-Partitionierung? Wo wird das Ergebnis der Reduce-Phase üblicherweise gespeichert? Was bedeutet dies für Failover?
| Zusätzliches Material | |
|---|---|
| Literatur | |
1.3 Übersicht über die Modellierungsschritte
Wie gelange ich von einem Szenario aus der realen Welt zu einer konkreten Datenbank? Was sind die verschiedenen Modellierungsschritte auf dem Weg dorthin? Was ist die Anforderungsanalyse? Und was passiert in dieser Phase? Was ist das Pflichtenheft? Und warum ist das wichtig? Was passiert im konzeptuellen Entwurf? Was mache ich mit dem konzeptuellen Entwurf? Was für Fallstricke gibt es bei der Umsetzung? Auf welcher Basis entwerfe ich das Datenbankschema? Warum durchlaufe ich all diese Modellierungsschritte überhaupt? Warum erzeuge ich nicht direkt das Datenbankschema?
| Zusätzliches Material | |
|---|---|
| Literatur | |

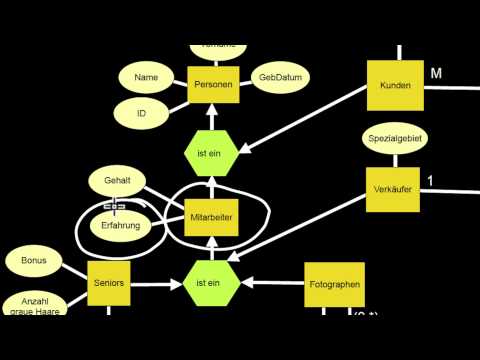
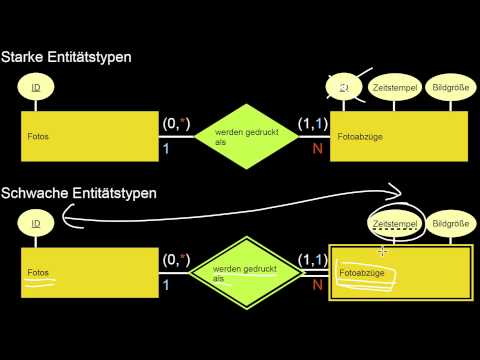
2.3 Schwache Entitätstypen, N:M, Generalisierung, Teil-von
Was sind schwache Entitätstypen und was ist deren Schlüssel? Was drückt ein schwacher Entitätstyp semantisch aus? Wie wird das notiert? Was hat das mit N:M-Beziehungen zu tun? Was ist eine Generalisierung? Wie wird sie notiert und gelesen? Was sind die Attribute eines Entitätstyps, der eine Generalisierung darstellt? Wie unterscheidet sich die Generalisierung von der Komposition (ist-Teil-von)? Und was sind da die Attribute?
| Zusätzliches Material | |
|---|---|
| Literatur | |
3 Relationales Modell
Was sind die wesentlichen Elemente des Relationalen Modells? Was ist eine Domäne und was ist ein Wertebereich? Was ist eine Ausprägung? Was ist ein Relationenschema und wie unterscheidet es sich von einer Relation? Was ist ein Tupel? Was ist ein Schlüssel? Was ist ein Kandidatenschlüssel und wie unterscheidet er sich von einem Primärschlüssel?
| Zusätzliches Material | |
|---|---|
| Literatur | |

4.3 Schwache Entitätstypen, Generalisierung
Wie werden schwache Entitätstypen ins relationale Modell übersetzt? Was passiert mit den Schlüsseln? Welche vier Optionen gibt es für die Übersetzung der Generalisierung? Was ist vertikale Partitionierung? Was sind die Vor- und Nachteile? Was ist Schemavereinigung mit und ohne Tupelredundanz? Zu welchen Redundanzen führen die verschiedenen Optionen? Sind diese Redundanzen grundsätzlich zu vermeiden?
| Zusätzliches Material | |
|---|---|
| Literatur | |
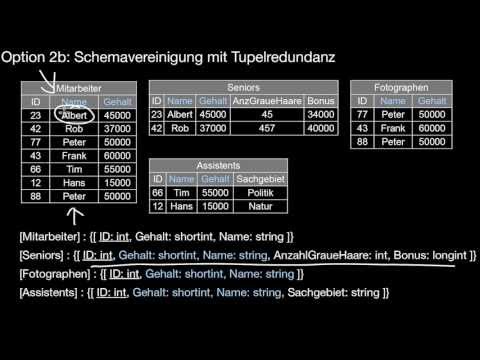
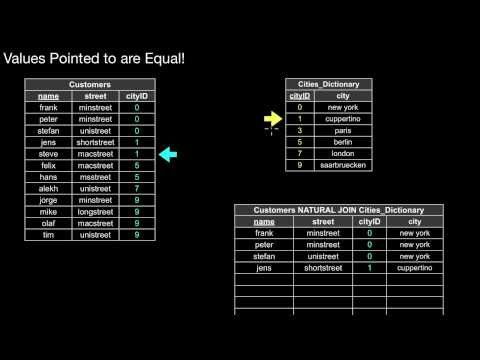
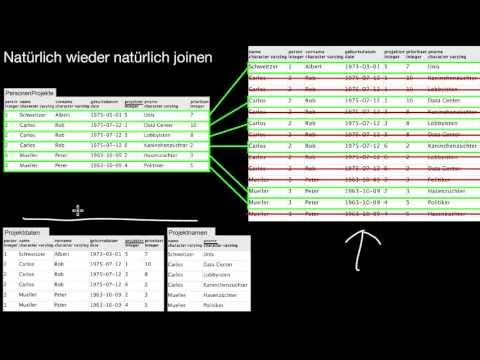
5.3 Abgeleitete Operatoren: Schnitt, Theta Join, Equi Join, Natural Join
Wie ermittle ich den Schnitt zweier Relationen und wann darf ich das machen? Wie kann ich den Schnitt mit Hilfe der Basisoperatoren der relationalen Algebra darstellen? Wie verbinde (joine) ich Daten aus verschiedenen Relationen? Was ist ein Theta-Join und wie hängt er zusammen mit dem Kreuzprodukt? Was ist ein Equi-Join und wie ist er definiert? Was ist ein Natural Join und wie hängt er mit dem Equi Join zusammen? Was haben Equi-Joins mit Beziehungstypen zu tun?
| Zusätzliches Material | |
|---|---|
| Literatur | |

6.3 Postgres Übersicht, Schema und Daten laden
Wie lade ich das \href{http://infosys.uni-saarland.de/datenbankenlernen/schema.sql{Beispielschema und die \href{http://infosys.uni-saarland.de/datenbankenlernen/data.sql{Beispieldaten der Fotoagentur in PostgreSQL? Wie stelle ich Anfragen im PostgreSQL-Interface?
| Zusätzliches Material | |
|---|---|
| Literatur | |
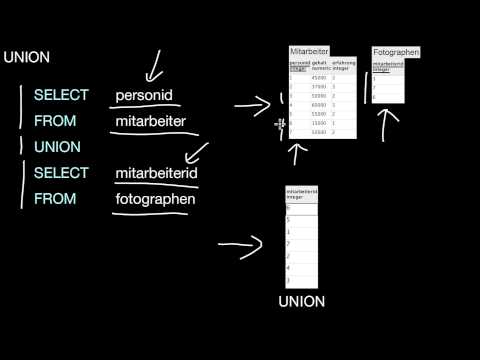
7.3 Binäre Operationen
7.3.1 UNION
Was machen UNION und UNION ALL prinzipiell? Wie unterscheiden sie sich von der relationalen Algebra? Wann darf ich UNION benutzen?
| Zusätzliches Material | |
|---|---|
| Literatur | |
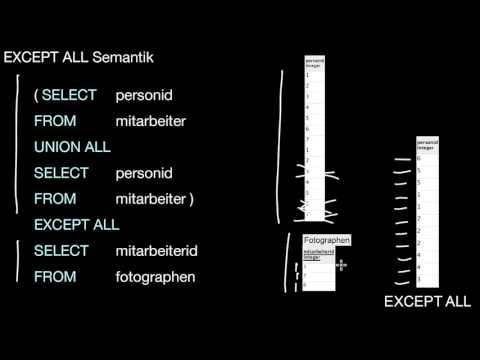
7.3.2 EXCEPT
Was machen EXCEPT und EXCEPT ALL prinzipiell? Wie unterscheiden sie sich von der relationalen Algebra? Wann darf ich EXCEPT benutzen?
| Zusätzliches Material | |
|---|---|
| Literatur | |
7.3.3 INTERSECT
Was machen INTERSECT und INTERSECT ALL prinzipiell? Wie unterscheiden sie sich von der relationalen Algebra? Wann darf ich INTERSECT benutzen?
| Zusätzliches Material | |
|---|---|
| Literatur | |

8.3 Integritätsbedingungen
Was passiert mit abhängigen Tupeln, die Tupel referenzieren, die gelöscht oder geändert werden? Wie kann ich beeinflussen, was mit diesen Tupeln passiert? Was sind die Optionen? Was macht DROP TABLE CASCADE? Was hat das mit dem Datenbankschema zu tun?
| Zusätzliches Material | |
|---|---|
| Literatur | |
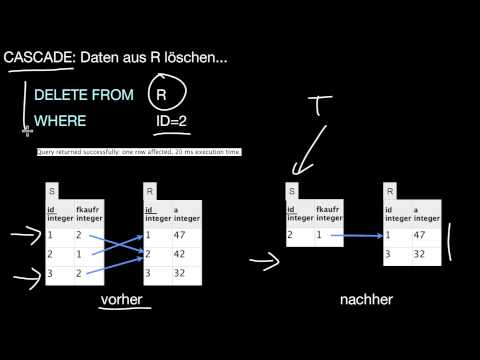
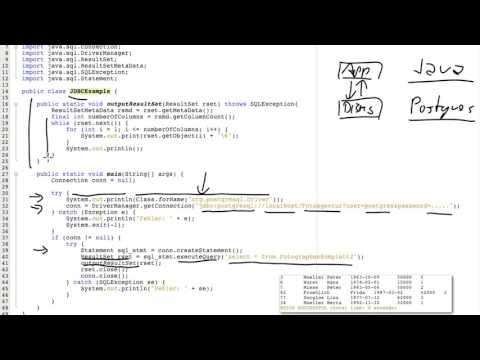
9.3 JDBC
Wie nutze ich ein DBMS aus einem Programm heraus? Welche Gefahren gibt es dabei? Was ist eine SQL-Injection-Attacke? Und wie vermeide ich sie durch Prepared Statements? Was ist JDBC?
| Zusätzliches Material | |
|---|---|
| Literatur | |
10.3 Superschlüssel, Kandidatenschlüssel, Primattribute, Triviale FD, Erste und Zweite Normalform
Was haben Funktionale Abhängigkeiten mit Schlüsseln zu tun? Wie kann man mit Hilfe von Funktionalen Abhängigkeiten Schlüssel erkennen und definieren? Wie unterscheiden sich Superschlüssel von Kandidatenschlüsseln? Wie unterscheiden sich Kandidatenschlüssel von Primärschlüsseln? Wieviele Superschlüssel, Kandidatenschlüsseln und Primärschlüsseln kann es für eine Relation geben? Was sind Prim- und was sind Nicht-Primattribute? Wann ist eine Funktionale Abhängigkeit trivial? Was ist die Erste Normalform (1NF)? Was ist die Zweite Normalform (2NF) und warum ist diese nicht wirklich wichtig?
| Zusätzliches Material | |
|---|---|
| Literatur | |

2.4 Sichtenkonsolidierung
Warum brauche ich Sichtenkonsolidierung? Was ist das? Wie hängt das mit den Sichten der logischen Datenunabhängigkeit zusammen? Welche Probleme können bei der Sichtenkonsolidierung auftauchen? Und wie löse ich sie? Was sind Vor- und Nachteile von left-deep versus bushy tree Konsolidierungen?
| Zusätzliches Material | |
|---|---|
| Literatur | |
5.4 Abgeleitete Operatoren: Semi Joins, Anti Semi Joins
Was sind Semi-Joins? Wie hängen diese mit Joins, wie hängen sie mit der Selektion zusammen? Wofür sind diese Joins nützlich? Was ist ein Anti Semi-Join? Wofür sind diese Joins nützlich?
| Zusätzliches Material | |
|---|---|
| Literatur | |

7.4 Joins
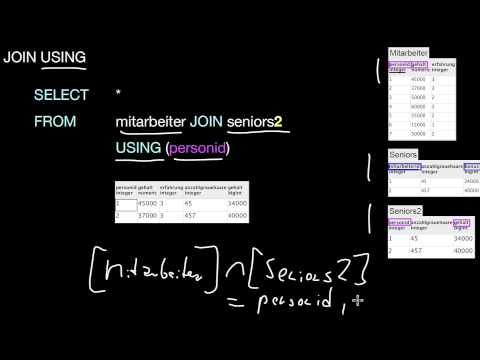
7.4.2 Äußere Joins
Was sind äußere (outer) Joins? Wie sind die verschiedenen Varianten (left, right, full) definiert? Wie hängen diese mit dem INNER JOIN zusammen? Wofür sind die äußeren Joins nützlich?
| Zusätzliches Material | |
|---|---|
| Literatur | |

10.4 Dritte Normalform 3NF
Was sind die Kriterien der Dritten Normalform (3NF)? Wann ist ein Relationenschema in 3NF?
| Zusätzliches Material | |
|---|---|
| Literatur | |


5.5 Abgeleitete Operatoren: Äußere Joins
Was ist ein äußerer Verbund (outer join)? Wie werden diese mit den Basisoperatoren ausgedrückt? Wozu sind left, right und full outer join nützlich?
| Zusätzliches Material | |
|---|---|
| Literatur | |

7.5 Gruppierung und Aggregation
7.5.1 GROUP BY
Wie setze ich Gruppierung und Aggregation der relationalen Algebra in SQL um? Wie unterscheidet sich die Aggregation von der Gruppierung? Wie ist die konzeptuelle Ausführungsreihenfolge der beiden Operationen? Wieviele Aggregatfunktionen dürfen im SELECT stehen? Welche Attribute dürfen im SELECT stehen und in welcher Form? Welche Attribute müssen zwar nicht aber sollten im SELECT stehen? Was sind die Unterschiede im Anfrageergebnis bei verschiedenenen DBMS? Wie hängt die Gruppierung mit der Duplikateliminierung zusammen? Wie hängt sie mit der Projektion zusammen?
| Zusätzliches Material | |
|---|---|
| Literatur | |

7.5.2 HAVING
Was ermöglicht HAVING? Und wie ist die konzeptuelle Ausführungsreihenfolge einer SQL-Anfrage mit HAVING? Wie unterscheidet sich HAVING von WHERE? Kann ich beide zusammen benutzen? Wie kann ich eine Anfrage mit HAVING-Semantik ohne HAVING-Statement umsetzen?
| Zusätzliches Material | |
|---|---|
| Literatur | |

10.5 Boyce-Codd Normalform BCNF
Was sind die Kriterien der Boyce-Codd Normalform (BCNF)? Wann ist ein Relationenschema in BCNF? Wann kann eine Tabelle überhaupt in 3NF sein und trotzdem BCNF verletzten? Kann eine Relation in BCNF sein aber nicht in 3NF?
| Zusätzliches Material | |
|---|---|
| Literatur | |

5.6 Erweiterungen: Gruppierung und Aggregation
Wie werden Daten gruppiert und aggregiert? Und warum wird dabei auch noch projiziert? Welche Attribute dürfen in der Projektion stehen und welche nicht? Was ist das Ergebnis einer Gruppierung mit Aggregation? Was ist das Schema? Wieviele Tupel enthält das Ergebnis? Kann ich aggregieren ohne zu gruppieren? Kann ich gruppieren ohne zu aggregieren?
| Zusätzliches Material | |
|---|---|
| Literatur | |

7.6 Sichten
7.6.1 Grundlagen
Was ist eine Sicht? Wie definiere ich Sichten? Wann wird eine Sicht ausgeführt? Was kann eine Sicht und was kann sie nicht? Wann ist es sinnvoll Sichten zu nutzen? Wie hängen Sichten mit Logischer Datenunabhängigkeit zusammen? Sollte ich Sichten nur für letzteres benutzen?
| Zusätzliches Material | |
|---|---|
| Literatur | |
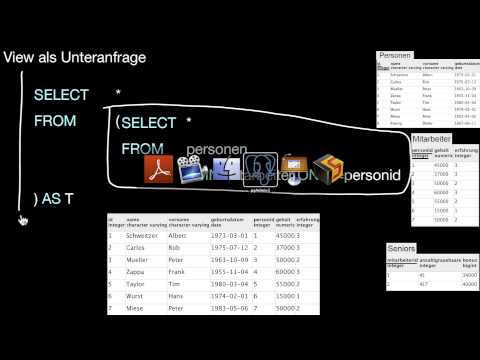
7.6.2 Lokale Sichten
Was ist eine lokale Sicht? Wie unterscheiden sich lokale Sichten von globalen Sichten?
| Zusätzliches Material | |
|---|---|
| Literatur | |

7.6.3 Tabellenfunktion
Was ist der Unterschied zwischen einer Sicht und einer Tabellenfunktion? Wie unterscheiden sich Tabellenfunktionen von anderen Funktionen? Wie erzeuge ich eine Tabellenfunktion? Wie lege ich das Schema der Tabellenfunktion fest?
| Zusätzliches Material | |
|---|---|
| Literatur | |

10.6 Inferenzregeln, Hülle
Was sind Inferenzregeln? Wie wende ich sie an? Was ist die Hülle F^+ einer Menge F Funktionaler Abhängigkeiten?
| Zusätzliches Material | |
|---|---|
| Literatur | |

7.7 NULL-Semantik
Was ist beim Filtern und Gruppieren zu beachten, wenn es NULL-Werte in einer der Eingaben gibt? In welchen Situationen spielt dies eine Rolle? Wie geht die Gruppierung mit NULL-Werten um? Was ist die dreiwertige Logik? Was ist die Rolle von IS NULL und IS NOT NULL?
| Zusätzliches Material | |
|---|---|
| Literatur | |

10.7 Zerlegung, gültig, verbundtreu, verlustlos, abhängigkeitsbewahrend
Welche Gütemaße sollte ich beachten, wenn ich ein Relationenschema zerlege? Wann ist eine Zerlegung gültig, verbundtreu (verlustlos), und/oder abhängigkeitsbewahrend? Was ist die Ausprägung einer Zerlegung? Welche Gütemaße muss bzw. kann ich mit Zerlegungen immer erreichen?
| Zusätzliches Material | |
|---|---|
| Literatur | |

7.8 PARTITION BY-Aggregation
Gibt es noch andere Möglichkeiten zu gruppieren und zu aggregieren als GROUP BY? Wie ist die konzeptuelle Ausführungsreihenfolge einer SQL-Anfrage mit PARTITION BY? Wieviele Tupel enthält das Ergebnis einer solchen Anfrage? Wie unterscheidet sich das Ergebnis prinzipiell von einem Ergebnis einer GROUP BY-Anfrage? Wie kann ich PARTITION BY ohne PARTITION BY-Statement mit einer Unteranfrage oder lokaler Sicht ausdrücken? Was ist die Rolle von OVER? Was erreiche ich mit WINDOW und wofür ist es eine Abkürzung? Kann ich GROUP BY und PARTITION BY kombinieren?
| Zusätzliches Material | |
|---|---|
| Literatur | |

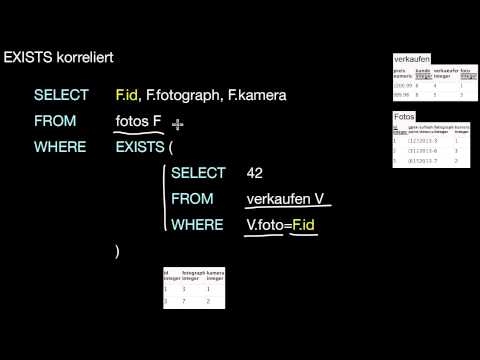
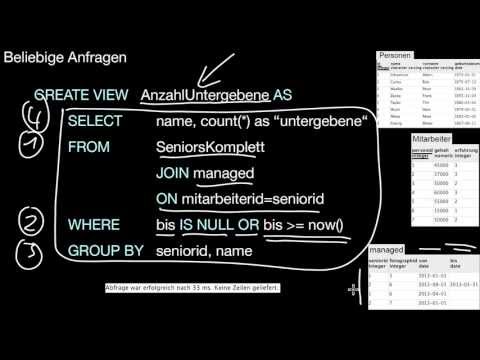
7.9 Unteranfragen
Was ist eine Unteranfrage? Wie funktionieren unkorrelierte und korrelierte Unteranfragen? Wie kann ich solche Unteranfragen lesen? Wie ist die Semantik von IN? Wie ist die Semantik von EXISTS? In welchen Abschnitten eines SQL-Statements sind Unteranfragen erlaubt? Wie kann ich Unteranfragen vereinfachen? Wie und wann kann ich Unteranfragen als (lokale) Sichten oder Joins formulieren?
| Zusätzliches Material | |
|---|---|
| Literatur | |